How to Multiply Across a Hierarchy in Oracle: Performance (Part 2/2)
In the first part I have shown several options to calculate aggregation functions along various branches of a hierarchy, where the values of a particular row depend on the values of its predecessors, specifically the current row’s value is the product of the values of its predecessors.
Performance was the elephant in the room. So, it’s time to take a look at the relative performance of the various alternatives presented.
Alternatives
We looked at roughly three alternatives in the previous post:
-
CONNECT BYwith the custom multiplication function, -
CONNECT BYwith the dynamic SQLevalfunction, - Recursive common table expression.
Because recursive common table expressions are still quite new to Oracle, hints can be ignored, which of course is of considerable interest to database developers who want to tune queries.
Note that for the eval function we actually have one more option, which is unique to Oracle Database 12c: a local function with the WITH syntax.
For future reference, let’s give these options shorter names:
-
CONNECT BYwith the custom multiplication function: mult; -
CONNECT BYwith the dynamic SQLevalfunction: eval; -
CONNECT BYwith the dynamic SQLevalin theWITHclause: with; - Recursive common table expression: cte.
Performance: Set-Up
For the performance tests I have used an Oracle Database 12c on a virtual machine with a clean instance that only ran my queries sequentially and nothing else.
I have looked at the metrics from the v$sql view and used autotrace in SQL Developer.
In case you’re interested, all code is available on GitHub.
Because the UPDATE statement that eliminates cyclic references can be very slow, I have placed the original script’s contents in a procedure called prepare_hierarchy_table, so that I can let Oracle run while I’m away.
The procedure prepare_table inserts the data according to the specified seed and number of rows.
Inside run_mult_stmt I have entered the various queries as strings, which are then executed with EXECUTE IMMEDIATE; there is a slight overhead to do it in this way, but it allows me to automate the tests and the overhead is roughly the same for each statement.
Since Oracle does not execute queries that do not return values in EXECUTE IMMEDIATE statements, the execution is wrapped in a dummy fetch: the average of the yield_to_step column values, which obviously depends on the particulars of the hierarchy, which ensures that Oracle does not take any shortcuts that could skew the results.
DECLARE
TYPE seed_arr IS VARRAY(4) OF BINARY_INTEGER;
TYPE rows_arr IS VARRAY(5) OF NUMBER;
TYPE meth_arr IS VARRAY(4) OF VARCHAR2(5);
l_seeds seed_arr := seed_arr(42, 429, 4862, 58786);
l_rows rows_arr := rows_arr();
l_methods meth_arr := meth_arr('cte', 'eval', 'mult', 'with');
l_value NUMBER;
l_start_ts TIMESTAMP;
l_end_ts TIMESTAMP;
BEGIN
l_rows.EXTEND(5);
DELETE FROM hierarchy_example;
COMMIT;
DBMS_OUTPUT.PUT_LINE('Seed,Rows,Method,Value,Elapsed');
<< rows_loop >>
FOR row_idx IN 1..l_rows.COUNT LOOP
l_rows(row_idx) := POWER( 10, row_idx );
<< seeds_loop >>
FOR seed_idx IN 1..l_seeds.COUNT LOOP
prepare_table( l_seeds(seed_idx), l_rows(row_idx) );
<< methods_loop >>
FOR meth_idx IN 1..l_methods.COUNT LOOP
-- ensure a similar environment for each run
EXECUTE IMMEDIATE 'ALTER SYSTEM FLUSH buffer_cache';
EXECUTE IMMEDIATE 'ALTER SYSTEM FLUSH shared_pool';
l_start_ts := SYSTIMESTAMP;
l_value := run_mult_stmt( l_methods(meth_idx) );
l_end_ts := SYSTIMESTAMP;
-- cross-check with hierarchy_stats
DBMS_OUTPUT.PUT_LINE
(
TO_CHAR( l_seeds(seed_idx) ) || ',' ||
TO_CHAR( l_rows(row_idx) ) || ',' ||
TO_CHAR( l_methods(meth_idx) ) || ',' ||
TO_CHAR( l_value ) || ',' ||
TO_CHAR( l_end_ts - l_start_ts )
);
INSERT INTO
hierarchy_stats
SELECT
SYSDATE
, l_seeds(seed_idx)
, l_rows(row_idx)
, l_methods(meth_idx)
, cpu_time
, elapsed_time
, sharable_mem
, persistent_mem
, runtime_mem
, sorts
, fetches
, executions
, buffer_gets
, plsql_exec_time
, rows_processed
FROM
v$sql
WHERE
REGEXP_LIKE(sql_text, '(SELECT|WITH|WITH FUNCTION) /*--' || l_methods(meth_idx) || '--*/');
COMMIT;
END LOOP methods_loop;
DELETE FROM hierarchy_example;
COMMIT;
END LOOP seeds_loop;
END LOOP rows_loop;
END;
By the way, the seed values are the sixth (n = 5), eighth (n = 7), tenth (n = 9), and twelfth (n = 11) Catalan numbers; they are in no way special other than that the sequence of numbers they belong to has a name.
Performance: Comparison
SQL performance can be regarded from several angles: execution plans, elapsed time, v$sql (runtime) metrics, and autotrace.
For each of the four queries we shall take a look at the relevant details.
Execution Plans and Autotrace
The easiest are the execution plans that the optimizer computes based on the minimal cost of all operations combined. Both the execution plan and the runtime statistics can be grabbed in one go with the autotrace, which makes it such a nice feature. Below I have displayed the output from SQL*Plus for each of the four SQL statements. I have used the same table with 1,000 rows for all four queries.
It is clear that mult requires the most consistent gets and memory sorts. The execution plan is also quite involved because of the double hierarchical structure discussed previously. The query does, however, use the index but that is a petty comfort, especially when we look at run times a bit later on. The cte is clearly more efficient, even though its execution plan includes two nested loops. So, it seems that Oracle made the right decision to support recursive factored subqueries.
When comparing eval to with it is also obvious that the latter requires fewer consistent gets but the former uses fewer recursive calls.
The main advantage of embedding the PL/SQL function in the SQL statement comes from minimizing context switches.
The eval function is a user-defined function and therefore requires two context switches for each invocation: one from SQL executor to PL/SQL engine and another one on the way back when the PL/SQL engine has determined the correct result.
Actually, we incur another two context switches inside the function because a SQL statement is wrapped inside the PL/SQL function.
All in all, we end up with the following logical flow: query (SQL) → function (PL/SQL) → NDS (SQL) → function (PL/SQL) → query (SQL).
By putting the function in the WITH clause of the query we can minimize these potentially expensive context switches.
It’s not all peachy though.
There are three disadvantages to the ‘functional WITH’ method:
- lack of modularity: you cannot reuse the function outside of the query it’s embedded in;
- aesthetics: SQL and PL/SQL are intermixed, which hampers the readability of your SQL statements;
- it is currently only available in Oracle Database 12c.
SQL Statement: mult
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 47 | 1833 | 596 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 39 | | |
|* 2 | CONNECT BY WITH FILTERING | | | | | |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED | HIERARCHY_EXAMPLE | 1 | 11 | 7 (0)| 00:00:01 |
|* 4 | INDEX SKIP SCAN | IX_HIERARCHY | 1 | | 6 (0)| 00:00:01 |
| 5 | NESTED LOOPS | | 1 | 24 | 14 (0)| 00:00:01 |
| 6 | CONNECT BY PUMP | | | | | |
| 7 | TABLE ACCESS BY INDEX ROWID BATCHED | HIERARCHY_EXAMPLE | 1 | 11 | 7 (0)| 00:00:01 |
|* 8 | INDEX SKIP SCAN | IX_HIERARCHY | 1 | | 6 (0)| 00:00:01 |
|* 9 | CONNECT BY NO FILTERING WITH START-WITH| | | | | |
| 10 | TABLE ACCESS FULL | HIERARCHY_EXAMPLE | 1000 | 11000 | 102 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access('I'.'ID'=PRIOR 'I'.'PRIOR_ID')
4 - access('I'.'ID'=:B1)
filter('I'.'ID'=:B1)
8 - access('I'.'ID'='connect$_by$_pump$_009'.'PRIOR i.prior_id $POS611')
filter('I'.'ID'='connect$_by$_pump$_009'.'PRIOR i.prior_id $POS611')
9 - access('O'.'PRIOR_ID'=PRIOR 'O'.'ID')
filter('O'.'PRIOR_ID' IS NULL)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
10520079 consistent gets
0 physical reads
0 redo size
139414 bytes sent via SQL*Net to client
1269 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client
30357 sorts (memory)
0 sorts (disk)
1000 rows processed
SQL Statement: cte
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 46 | 95680 | 240 (0)| 00:00:01 |
| 1 | VIEW | | 46 | 95680 | 240 (0)| 00:00:01 |
| 2 | UNION ALL (RECURSIVE WITH) BREADTH FIRST| | | | | |
|* 3 | TABLE ACCESS FULL | HIERARCHY_EXAMPLE | 18 | 198 | 102 (0)| 00:00:01 |
| 4 | NESTED LOOPS | | | | | |
| 5 | NESTED LOOPS | | 28 | 57456 | 138 (0)| 00:00:01 |
| 6 | RECURSIVE WITH PUMP | | | | | |
|* 7 | INDEX RANGE SCAN | IX_HIERARCHY | 2 | | 1 (0)| 00:00:01 |
| 8 | TABLE ACCESS BY INDEX ROWID | HIERARCHY_EXAMPLE | 2 | 22 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter('PRIOR_ID' IS NULL)
7 - access('D'.'PRIOR_ID'='R'.'ID')
filter('D'.'PRIOR_ID' IS NOT NULL)
Statistics
----------------------------------------------------------
4 recursive calls
0 db block gets
2148 consistent gets
0 physical reads
0 redo size
139882 bytes sent via SQL*Net to client
1269 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client
62 sorts (memory)
0 sorts (disk)
1000 rows processed
SQL Statement: eval
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 47 | 1833 | 102 (0)| 00:00:01 |
|* 1 | CONNECT BY NO FILTERING WITH START-WITH| | | | | |
| 2 | TABLE ACCESS FULL | HIERARCHY_EXAMPLE | 1000 | 11000 | 102 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access('PRIOR_ID'=PRIOR 'ID')
filter('PRIOR_ID' IS NULL)
Statistics
----------------------------------------------------------
68 recursive calls
0 db block gets
417 consistent gets
0 physical reads
0 redo size
157997 bytes sent via SQL*Net to client
1269 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
1000 rows processed
SQL Statement: with
---------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 47 | 1833 | 102 (0)| 00:00:01 |
|* 1 | CONNECT BY NO FILTERING WITH START-WITH | | | | | |
| 2 | TABLE ACCESS FULL | HIERARCHY_EXAMPLE | 1000 | 11000 | 102 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access('PRIOR_ID'=PRIOR 'ID')
filter('PRIOR_ID' IS NULL)
Statistics
----------------------------------------------------------
151 recursive calls
0 db block gets
374 consistent gets
0 physical reads
0 redo size
36537 bytes sent via SQL*Net to client
900 bytes received via SQL*Net from client
19 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
1000 rows processed
Run Times
Typically, the run times are skewed by whatever is else happening on the database server, how much stuff resides in the cache, and so on.
Because I ran nothing but the script on the VM, the results from v$sql should not be far from the truth, especially since I ran the script multiple times.
Shown in the chart below is the runtime performance, in particular the median CPU time and the mean number of buffer gets, both normalized to the mean of all runs for source tables with 10,000 rows. The error bars in the top chart are the minimum and maximum values from all runs.
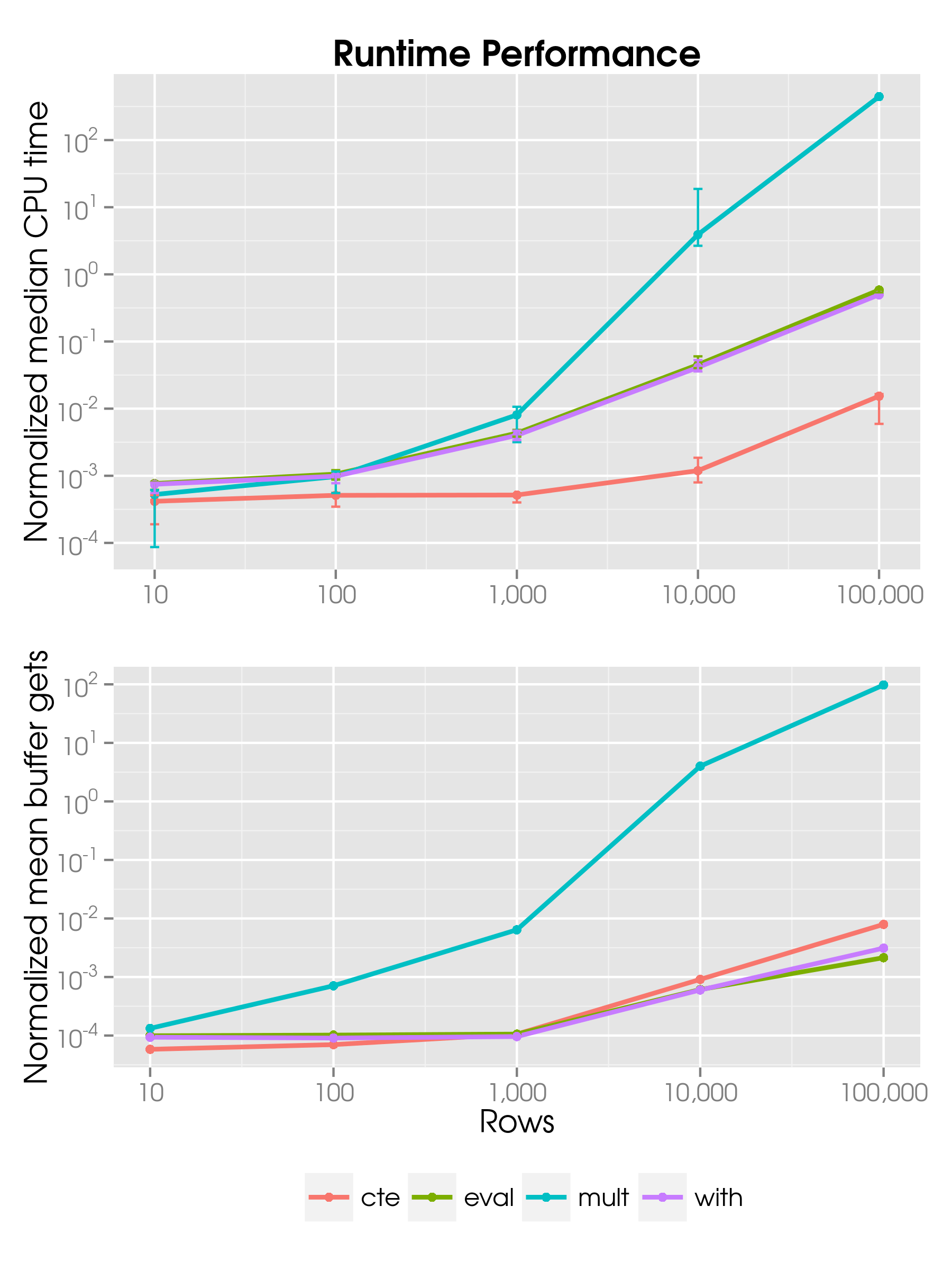
It is clear that the common table expression is the fastest when trying to multiply across a hierarchy. The original solution with the nested hierarchies (mult) is by far the slowest. Interestingly, I did not find a noticeable difference between the eval and with methods, which seems to indicate that for this kind of problem the context switches are not a significant factor contributing to runtime performance degradation. The with method is, however, consistently faster than the eval method, even though only slightly so.
I did not go beyond 100,000 rows because either it took too long to ensure that there were no cyclic references in the hierarchy or Oracle ran out of memory during the table preparation; CONNECT BY can be a bit heavy on the memory.
Because most queries ran so slowly for tables with 100,000 rows, only cte has minimum and maximum values listed next to its median CPU time.
I obtained these metrics with the help of the following simple query, which includes a few more :
SELECT
num_rows
, method_name
, ROUND(AVG(1E-6 * cpu_time), 5) AS avg_cpu_time_sec
, ROUND(STDDEV(1E-6 * cpu_time), 5) AS std_cpu_time_sec
, ROUND(MEDIAN(1E-6 * cpu_time), 5) AS med_cpu_time_sec
, ROUND(MIN(1E-6 * cpu_time), 5) AS min_cpu_time_sec
, ROUND(MAX(1E-6 * cpu_time), 5) AS max_cpu_time_sec
, ROUND(AVG(1E-6 * elapsed_time), 5) AS avg_elapsed_time_sec
, ROUND(STDDEV(1E-6 * elapsed_time), 5) AS std_elapsed_time_sec
, ROUND(MEDIAN(1E-6 * elapsed_time), 5) AS med_elapsed_time_sec
, ROUND(MIN(1E-6 * elapsed_time), 5) AS min_elapsed_time_sec
, ROUND(MAX(1E-6 * elapsed_time), 5) AS max_elapsed_time_sec
, ROUND(AVG(1E-6 * plsql_exec_time), 5) AS avg_plsql_exec_time_sec
, ROUND(STDDEV(1E-6 * plsql_exec_time), 5) AS std_plsql_exec_time_sec
, ROUND(MEDIAN(1E-6 * plsql_exec_time), 5) AS med_plsql_exec_time_sec
, ROUND(MIN(1E-6 * plsql_exec_time), 5) AS min_plsql_exec_time_sec
, ROUND(MAX(1E-6 * plsql_exec_time), 5) AS max_plsql_exec_time_sec
, ROUND(AVG(sharable_mem / 1024), 2) AS avg_sharable_mem_mb
, ROUND(AVG(persistent_mem / 1024), 2) AS avg_persistent_mem_mb
, ROUND(AVG(runtime_mem / 1024), 2) AS avg_runtime_mem_mb
, ROUND(AVG(buffer_gets)) AS avg_buffer_gets
FROM
hierarchy_stats
GROUP BY
num_rows
, method_name
ORDER BY
num_rows
, method_name;
Summary
Oracle offers at least four solutions to multiply across a hierarchy. Some are compact (eval and to a lesser extent with), some are size-wise not too bad but horribly inefficient (mult), while another is a bit more work when typing but quite speedy (cte).
When you are dealing with small tables (fewer than 1,000 rows), the SQL statement that you write really depends on your syntax aesthetics: the run times do not differ too much, so you can pick whichever you like best.
For tables with more than 1,000 rows, it is obvious that you should stay away from nested hierarchical queries (mult) and go with factored subqueries, provided that your Oracle release supports them of course.
If not, you can use the solution with native dynamic SQL (i.e. eval), since the WITH syntax with PL/SQL functions is only available in 12c.