Machine Learning Platforms in 2021
How many machine learning platforms run on Kubernetes? Which machine learning platforms can run in air-gapped environments? How common are feature stores in current machine learning platforms?
There are many commercial and open-source machine learning platforms on the market today. While Gartner’s Magic Quadrants and Forrester’s Waves can inform, these views onto the marketplace are not neutral: they are based on vendor demonstrations and customer surveys rather than hands-on software evaluations or in-depth studies of available documentation. The majority of solutions available to enterprises are not even listed.
Portions of this article are also available as a recorded conference talk (30 min) at Scaling Continuous Delivery.
Infrastructure
In the Sankey diagram below you can see which products fall into which categories and what the infrastructure layer underneath is:
- VMs (or servers / bare metal)
- Python
- Docker
- Kubernetes
- Managed (or SaaS)
Python is the oddball in the list: several technologies require Python to be present as they are essentially libraries on top of it, but they are not containerized by default.
It is obvious that Kubernetes has become the standard infrastructure for machine learning platforms, even for platforms that rely on VMs or bare metal for model development; they typically depend on Kubernetes for deployments. It is inside half of all platforms considered, and it powers more than 60% of non-managed end-to-end machine learning platforms.
Not all Kubernetes-based platforms are created equal: some require managed Kubernetes services (e.g. AKS, EKS, GKE), while others can only run on specific Kubernetes distributions (e.g. Konvoy, OpenShift). Platforms that can run on any Kubernetes installation rarely come with all the tools needed for production deployments (e.g. authentication, authorization, auditability, observability, multi-tenancy, and cost management), which means they still require a fair amount of glue code to be squeezed into the cracks.
Hover over the links in the diagram to see lists of platforms.
For end-to-end machine learning platforms (53):
- 45% run on Kubernetes (24)
- 26% are managed services (14)
- 15% run on VMs or plain servers (8)
- 6% run on Docker (3)
- 4% run on Hadoop (2)
- 4% run on Python (2)
Kubeflow, especially Kubeflow Pipelines is inside a few platforms, including AWS SageMaker and GCP AI Platform. In fact, 38% of end-to-end machine learning platforms on Kubernetes (24) are based on at least one Kubeflow component (9). Kubeflow Pipelines is used by organizations such as Spotify, CERN, Nubank, Snap, Leboncoin, Lifen, and Zeals.
Note that proprietary enterprise platforms occasionally offer restricted open-source solutions for individuals. The enterprise editions are nevertheless rarely open source, which is what is shown here.
Development + Deployment ≠ End-to-End
While it is definitely possible to DIY an end-to-end machine learning platform by combining development and deployment solutions, it is far more common to offer the whole package in one product:
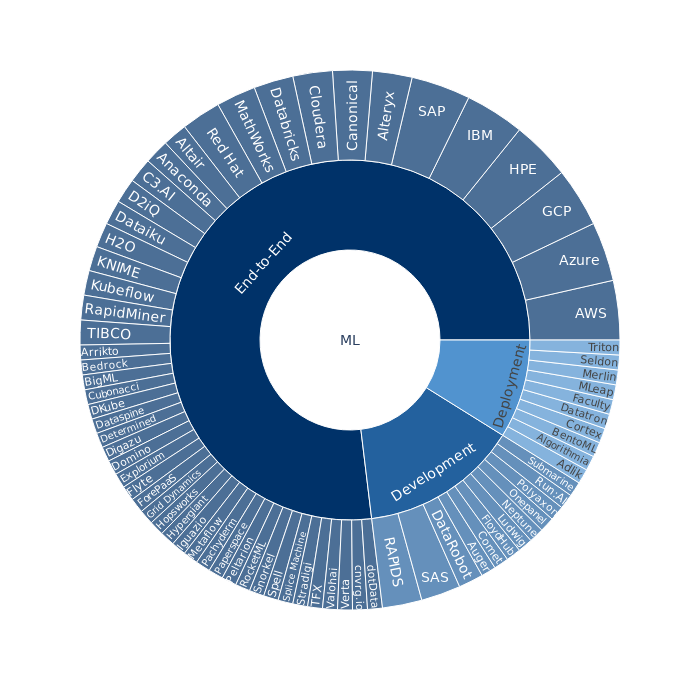
Most end-to-end platforms offer a lot more than merely a development environment and infrastructure for model deployments. Model lifecycle management, observability, end-to-end security, cost management are but a few such components typically found in end-to-end platforms. It explains why more than 80% of end-to-end machine learning platforms are proprietary.
On-Premise vs Cloud
There is no doubt that the cloud is chipping away at on-premise data centres. The imminent death of the on-premise data centre has, however, been greatly exaggerated, especially with up to 70 billion terabytes to be stored in on-premise data centres over the next few years.
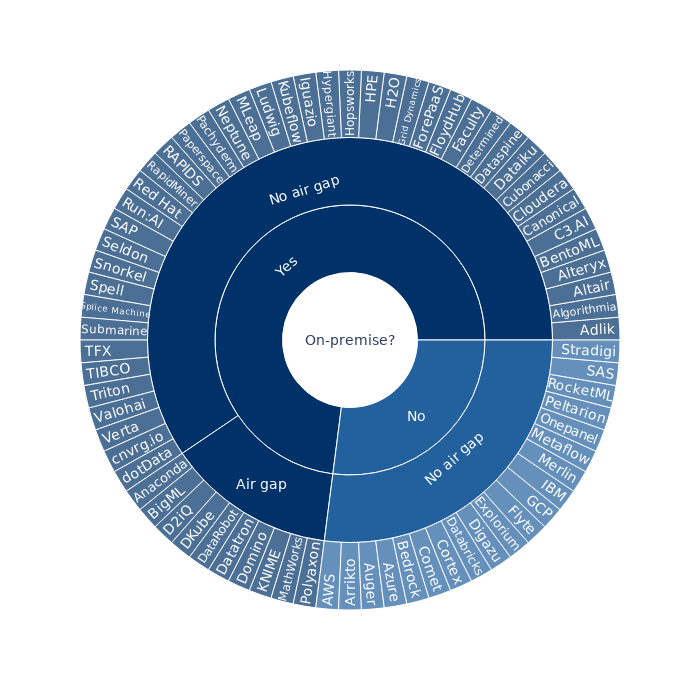
The majority of machine learning platforms can be deployed on premises. Platforms with support for on-premise deployments can typically run in the cloud, too.
What is rare is support for air-gapped or fully offline environments, as can be seen in the chart. Please note that if a platform can theoretically be deployed in air-gapped environments but that process is not publicly documented, it is not shown in the “air gap” category. From experience, it is easy to claim that an air-gapped deployment is possible, but a lot harder to achieve.
Are air-gapped clusters really that prevalent? Quite a few companies in manufacturing, government, intelligence, military, pharmaceuticals, banking, and insurance still depend on their own offline data centres for critical infrastructure.
Code vs No/Low Code
While no-code platforms democratize machine learning, products that require data scientists to code are far more common:
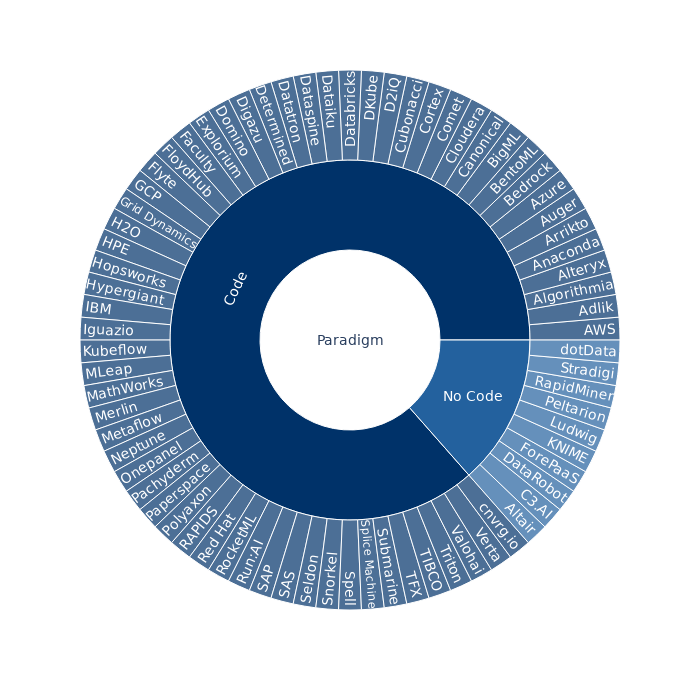
Note that no-code solutions all suffer from the same problems as visual programming languages in data engineering.
Feature Stores
While most tech companies have feature stores in their machine learning platforms, they are still fairly rare in commercial offerings:
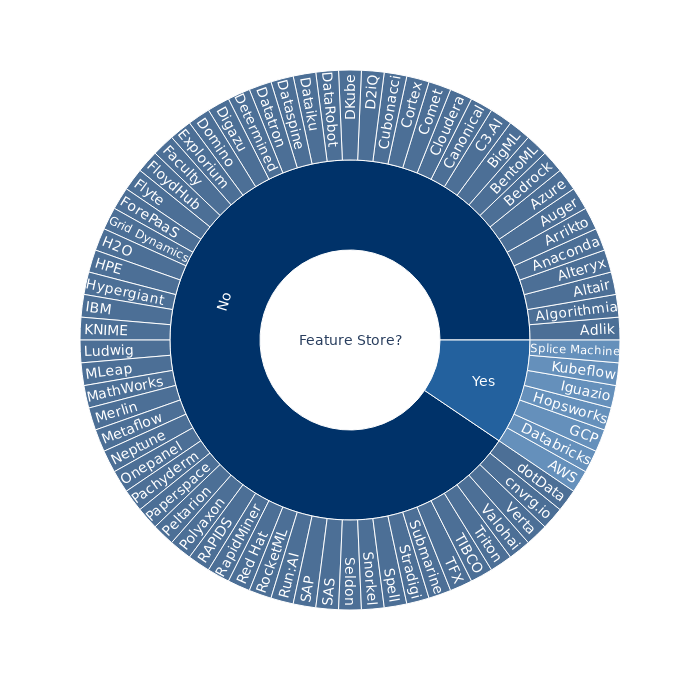
Google announced in September they would add a managed feature store to GCP’s AI Platform by the end of 2020. It took them a little longer with the rebranding to GCP Vertex AI.
List of Platforms
The list of 75 platforms that I have considered is in alphabetical order with year of launch of each product (or company):
- Adlik (2020)
- Altair Knowledge Studio (2014)
- Algorithmia (2014)
- Alteryx (2020)
- Anaconda Enterprise (2020)
- Arrikto Enterprise Kubeflow (2019)
- Auger (2019)
- AWS SageMaker (2017)
- Azure ML (2019)
- Basis AI Bedrock (2018)
- BentoML (2019)
- BigML (2015)
- C3.AI (2009)
- Canonical Charmed Kubeflow (2019)
- Cloudera ML (2019)
- cnvrg.io (2016)
- Comet (2017)
- Cortex (2019) (defunct)
- Cubonacci (2018) (defunct)
- D2iQ Kaptain (2020)
- Databricks Data Science Workspace (2013)
- Dataiku (2013)
- DataRobot (2012)
- Dataspine (2017) (defunct)
- Datatron (2016)
- Determined AI (2020)
- Digazu (2018)
- One Convergence DKube (2018)
- Domino Data Lab (2013)
- dotData Enterprise (2018)
- Explorium Data Science Platform (2017) (defunct)
- Faculty (2014)
- FloydHub (2016)
- Flyte (2019)
- ForePaaS (2019)
- GCP Vertex AI (2019)
- Grid Dynamics (2010)
- H2O Driverless AI (2012)
- Logical Clocks Hopsworks (2016)
- HPE Ezmeral MLOps (2020)
- Hypergiant (2018)
- IBM Watson ML (2014)
- Iguazio (2014)
- KNIME (2008)
- Kubeflow (2018)
- Ludwig (2019)
- MathWorks ML toolboxes (2004)
- Merlin (2020)
- Metaflow (2019)
- MLeap (2016)
- Neptune (2017)
- Onepanel (2020)
- Pachyderm (2014)
- Paperspace Gradient (2014)
- Peltarion (2005) (defunct)
- PI.EXCHANGE (2019)
- Polyaxon (2018)
- RapidMiner (2007)
- RAPIDS (2018)
- Red Hat Open Data Hub (2019)
- RocketML (2017)
- Run:AI (2018)
- SAP ML Lab (2020)
- SAS Visual Data Mining and Machine Learning (2016)
- Seldon Core (2018)
- Snorkel (2016)
- Spell (2017) (defunct after acquisition by Reddit in 2022)
- Splice Machine ML Manager (2012)
- Stradigi Kepler (2004)
- Submarine (2020)
- TFX (2019)
- TIBCO Data Science (2018)
- NVIDIA Triton (2018)
- Valohai MLOps Platform (2016)
- Verta (2018)
The following open-source projects have been excluded as they appear to be defunct, having little or no activity in the past few months:
- Angel (2017): a development platform on Hadoop
- Clipper (2017): a deployment platform on Docker
- ForestFlow (2019): a deployment platform on Kubernetes
- Multi Model Server (2017): a deployment platform on Docker
- PredictionIO (2016): an end-to-end platform on Hadoop
FAQ
Why is Airflow not included?
Contrary to information floating online, in which Airflow is compared to any *flow (e.g. Kubeflow and MLflow), Airflow is a workflow orchestration platform. Airflow is not a machine learning platform.
Airflow is closest to Luigi, Dagster, DataBolt, Flyte, Kedro, Kubeflow Pipelines, Prefect, Tekton.
Why is MLflow not included?
MLflow (2018) deals with model lifecycle management. It is not a machine learning platform.
Why is »…« not included?
Because I either did not know about it or I did not have the time to look at it in detail yet.
What about PMML, PFA, and ONNX?
PMML, PFA and ONNX are formats to represent models at serving, which requires a scoring engine or inference runtime. As such, they are not standalone deployment platforms.
Framework-specific model servers, such as TensorFlow Serving and TorchServe are not listed explicitly either.
Hang on! Kubeflow is counted twice in the Sankey diagram. What’s up with that?
Kubeflow, as a node, indicates any component out of the Kubeflow project, such as Kubeflow Pipelines or its various Kubernetes operators for machine learning frameworks. As a platform—although toolkit is more appropriate as it lacks end-to-end integration tests and the majority of glue code needed to be considered a proper platform, Kubeflow is an entry of the vertex from Kubeflow (node) to Open Source.
Note that KFServing is not included as a deployment platform separately, as it is a part of the Kubeflow project.
Is the data guaranteed to be correct?
No. Feel free to send an email if you discover inaccuracies.