Why Govern Your Data?
The way a company looks at its data is indicative of its readiness to embrace a data governance programme: is data a by-product of doing business or an asset that requires attention and resources? One of the key questions with data governance is, ‘Why?’
Why should you govern your data? What’s the benefit?
To some data governance is logical, essential really. To others it may seem like frivolity or even utopia. Data governance is a mindset: it requires a fundamental shift in the mentality of all employees who work with data. Data that has been ‘managed’ from the bottom up, in which departments only care for the data that affects their line of business, suddenly has to be seen and managed from the top down: data is a corporate asset and it needs to be managed and secured that way. No longer is it acceptable to allow bad data to slip through the cracks and sully reports or even important decisions.
But what stands in the way of quality data are not just siloed data sources that need to be merged but fragmentation of the business and the us-vs-them view that characterizes many divisions, especially with regard to data. Sure, divisions may have spent ages on ‘their’ data, but more often than not the quality is nowhere near the amount of time they have put in or even what they perceive the quality to be. Many companies overestimate the quality of their data, which exacerbates the issue.
Having invested in the initial steps to data governance maturity, companies usually keep on going because it makes sense and has tangible benefits to the organization and its relationship with one of its core assets: data. So, how do you move across the threshold?
I have read The Data Asset by Tony Fisher a while ago, which I can highly recommend. It’s geared towards executives, although I believe it is a valuable addition to the libraries of more technical people too. He describes in great detail what data governance is, why it matters, and how to achieve it.
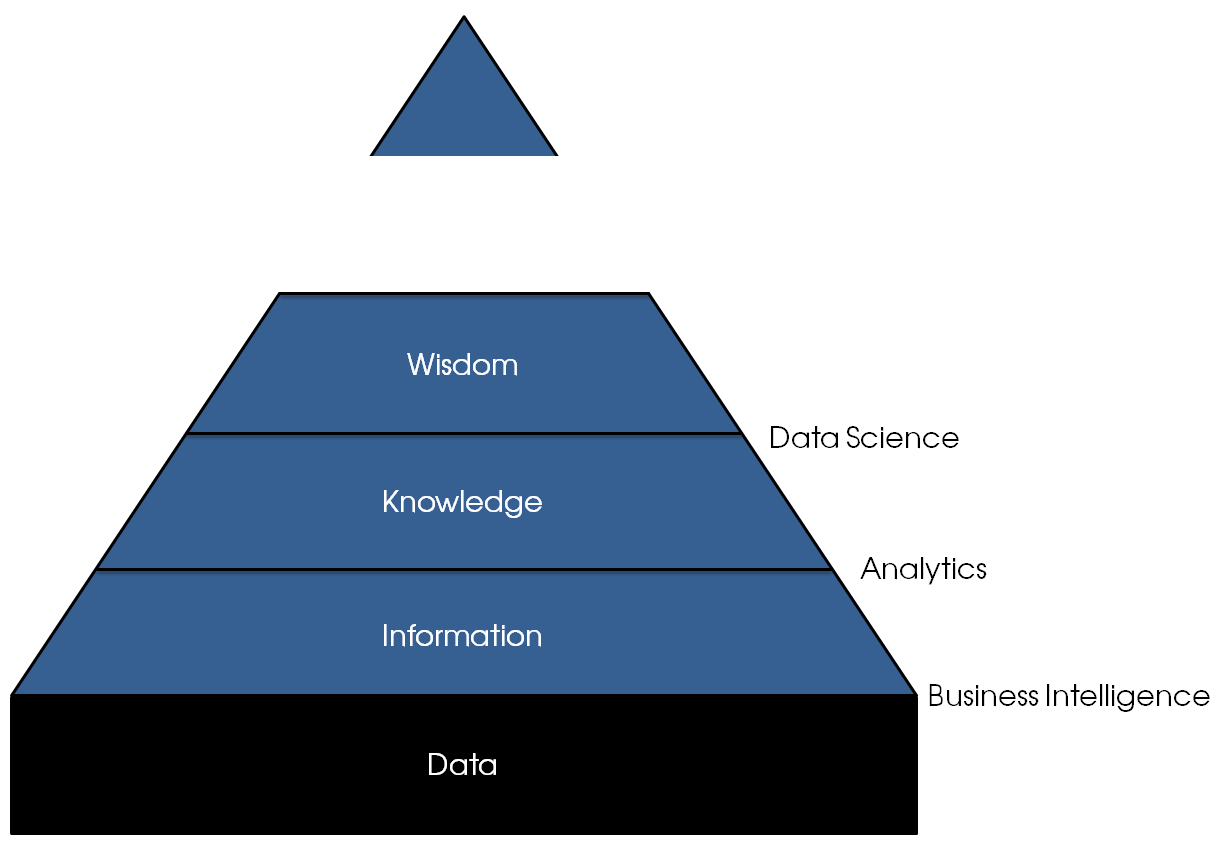
Data governance deals with more than data quality alone. Data quality pertains to the question “whether an organization’s data is reliable, consistent, up to date, free of duplication, and fit for its purposes,” as written by Tony Fisher. Data management is a critical component too. It is “a consistent methodology that ensures the deployment of timely and trusted data across the organization.” I have added the emphasis because the distinction is clear: data quality deals with the data itself and its interpretation (i.e. What?) , whereas data management deals with the method (i.e. How? Who?). That still leaves open the question, ‘Why?’
Before we come to an answer though, I want to briefly touch upon DQM and MDM, as DQM is relevant to answering why data governance is important.
DQM and MDM
Data Quality Management (DQM) is concerned with the processes, tools, and methods to analyse and cleanse data. MDM (i.e. Master Data Management) is about standardizing, administering, and storing data that is critical to the business. Without DQM, MDM stands very little chance. Similarly, without standardization, data quality cannot be maintained without an incredible effort. As such, DQM and MDM go hand in hand.
The main problems that affect the quality of data are:
- Timeliness: Is the data available when it is needed?
- Completeness: Is the required data also available?
- Correctness: Is the available data correct and pertinent?
- Consistency: Are all the data elements defined and understood consistently?
- Validity: Is the data within acceptable ranges?
Consistency pertains to both within the same source and across multiple sources; even within the same data source there can be significant differences if integrity of the data is not enforced.
The Cost of Dirty Data
Now let’s get back to the question of why you would want to initiate a data governance programme.
Many experts believe that issues with data quality (DQ) cost businesses around the globe up to a quarter of their revenue. An often quoted number is $600 billion per year for US businesses, which is based on a 2002 TDWI report, which slaps a price tag of $611 billion on postage, printing, and staff overhead due to low-quality customer data. Yes, that’s only customer data! Anyway, with an average data growth rate of 60%, there is no time like the present to darn the hole in the corporate money bag, especially one of that size.
The 1-10-100 rule is equally frequently mentioned: it costs $1 to verify a record when it is entered, $10 to cleanse and de-duplicate it afterwards, and $100 when nothing is done; the reason it costs a hundred bucks even when doing nothing at all is that the same mistakes are made over and over again.
A standard example of the impact of DQ on demand is provided by SiriusDecisions. If the number of usable records in a prospect database is raised from 75% to 90%, a 66% rise in revenue can be achieved because of better targeting and its positive side effects. Unfortunately, few reliable case studies on the details of poor-quality data exist.
An indirect way to obtain an estimate of the costs of scrubbing low-quality data is based on the time data scientists spend fixing DQ issues, which is not their core duty. You will often find data cleansing to be part of the job description, but a data scientist’s true value is in discovering patterns in data that others miss, not cleaning up after the rest.
According to a recent New York Times article, data scientists spend 50-80% of their time dealing with data quality issues. The reason companies employ data scientists is to obtain golden information nuggets from their companies’ various data sources. Theirs is not the task to tame unmanageable data or play the data caretakers, and — as I have written before — such tasks will likely lead to frustration, and frustration often leads to premature departure from a company.
Now let’s take a look at salaries for data scientists in the USA. The average salary is somewhere above the $100k mark, but for the purposes of our discussion, let’s settle on a solid $100,000 per annum. If data scientists spend on average 65% of their time whipping the data into shape before they can do something useful with it, then companies pay $65,000 per data scientist per year for things that have no immediate benefit. After all, data scientists are rarely involved in building data warehouses filled to the brim with data that is glistening with purity. They often clean up data on an ad hoc basis, which means that the same work is done several times by different people within the same organization.
So, how many data scientists are out there? An estimate from KDnuggets from March 2014 sets the number of people between 150,000 and 250,000 based on data from Kaggle and LinkedIn. Since a fair share of the people who fit the description of a data scientist is likely to live in the United States, we’ll again take a nice, rounded number for the number of US-based data scientists: 100,000. Consequently, bad data costs US companies $6.5 billion a year, which is a very low estimate as we have only looked at data scientists, whereas in fact many departments are affected by dirty data. Still, that’s a lot of money being thrown away on the sexiest job of the century, although such an epithet is quite presumptuous, having been introduced in the first eighth of the century.
If Gartner’s forecast may be trusted, 4.4 million jobs related to analytics will be created in the next two years. Assuming these vacancies will be filled and people spend about half their time scrubbing data sources, earning a more modest $75,000, we arrive at $82.5 billion wasted per year in addition to the money that is already going down the tube due to the lack of data governance.
Thomas Redman points out on HBR.org that there are also hidden costs: a loss of trust and lost opportunities. I have personally seen both, but I can say from experience that restoring faith is extremely difficult once people have expressed their dismay at the data contained in a central repository, such as a data warehouse. People often accept the flaws in ‘their’ data and know the workarounds, but once someone else takes their data and posts it on the company notice board, the flaws have magically become your problem and responsibility to fix. A lack of data ownership is often at the core of data quality issues: ‘If I’m not accountable, why bother?’
Why Bother?
While the vast majority of companies prevent or fix data defects at the source, a fair share of organizations fix errors downstream, in reports, or not at all. Confidence in business solutions decreases rapidly once data issues are discovered, and, as I have said, it is tough to restore it once it’s gone.
With the advent of Big Data and the related substantial investments that many companies are about to make, a question I have recently overhead is whether data governance is really worth it. After all, many vendors sell people on the promise of Big Data: feed the Moloch Machine ever more data and it will come up with even more insights. What they, or gullible customers, often forget to see is the small print that explains that only high-quality data will do. Feed it trash and it will give you hidden relations in the garbage can. If your carpet bulges because you have swept all dirt underneath, dragging in a bigger carpet is not the answer. All you will end up with is more room for dirt and a reminder that carpets are dirt magnets.
The same is true for data: more data does not magically solve all your woes. It does not dilute the data quality issues either. More data means more potential issues, and without data governance that potential will quickly materialize and cause real problems.
A manufacturing company that I worked with, tried (and failed) to get a Big Data project off the ground. They had previously attempted to build a data warehouse as a single source of information but only succeeded temporarily and partially. What I mean by that is that they did not succeed at all: a large portion of the data warehouse was consistent and clean for a certain amount of time, but as soon as the people involved moved away from the data warehouse and on to other projects, the data dirt started to accumulate again. Against our recommendations, they kicked off a Big Data initiative, for which even more data sources were to be included. What they discovered early on was that the data contained in the sources was too inconsistent to be useful. No amount of fancy algorithms could see beyond the obvious, and the few patterns the algorithms discovered were nothing but mirages, gone as soon as anyone with a bit of business know-how poked around in the data.
Where To Go From Here?
I hope the back-of-the-envelope calculations of the cost of dirty data have at least caused you to think, perhaps even act. Though it is already fourteen years old, the quote still rings true today:
For a director in charge of marketing, production or CRM to fail to take an interest in data management, or any responsibility for its quality, is a clear abdication of duty. PwC, Data Management Survey (2001)
In the Global Data Management Survey they conducted ten years later, PwC concluded that “few companies have established independent, cross-process and cross-functional data governance boards.”
When you come to the conclusion that data governance is necessary, you have made the first step towards data governance, albeit a very small one. You may know where you want to go, but without your current position you cannot reach the goal, at least not in the best way possible. To assess your organization’s information maturity, you can take a look at IM QuickScan, which is free. Once you know where you stand and where you want to go, you can create a road map.
The best way to initiate a data governance programme is from the top down: executive support is critical. Mind you, no organization can tackle all data quality issues at once, which is why a data governance programme often starts in one business area and then spreads out to others once the preliminary results are in. The inverted-T model is typically how an enterprise-wide data governance programme progresses: top-down in one area and then the results reach other departments that want in on the action.
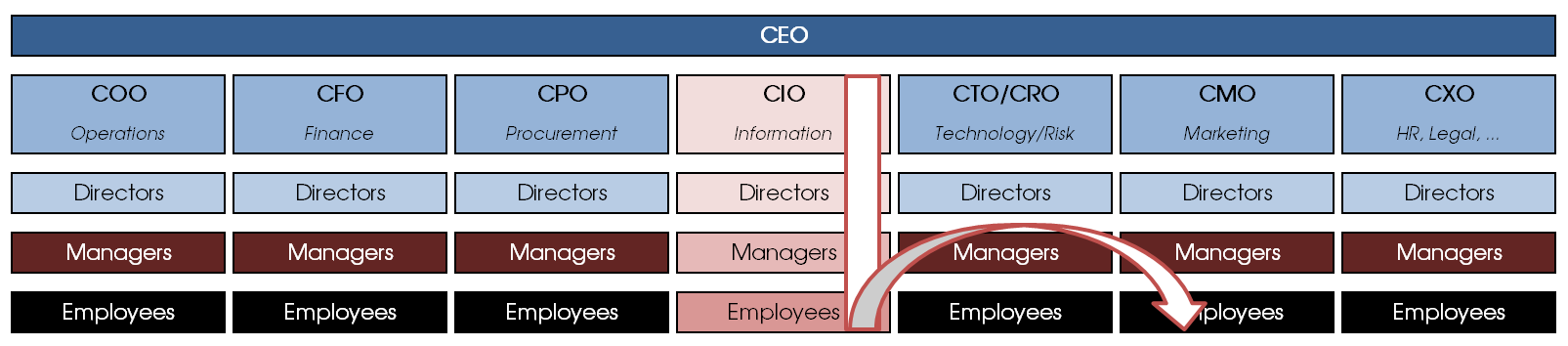
Spontaneous self-organization, whereby people wilfully reduce their own productivity to raise the overall data quality is rare, especially since the effort is enormous and there is no guarantee that others will appreciate the effort and stick to the rules laid out by a few mavericks. To be fair, I have not seen, heard of or read about bottom-up success stories with it comes to data governance, mainly because ownership and accountability remain unclear. Data decisions, such as naming conventions and data standards, can often bubble their way up, but a full-scale data governance programme is unlikely to appear from these humble efforts without executive support. I’d be happy to concede if anyone showed me an example though.
Sure, data governance is hard. Is that a reason not to do it? I think not. If businesses postpone the real challenges and only go for the low-hanging fruit they’ll miss out on many opportunities. Indeed, sometimes we need to tackle the hard problems because they are hard and necessary, and the rewards are bountiful:
We choose to go to the moon. We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard, because that goal will serve to organize and measure the best of our energies and skills, because that challenge is one that we are willing to accept, one we are unwilling to postpone, and one which we intend to win, and the others, too. John F. Kennedy (1962)