An Overview of File and Serialization Formats in Hadoop
Apache Hadoop is the de facto standard in Big Data platforms. It’s open source, it’s free, and its ecosystem is gargantuan. When dumping data into Hadoop, the question often arises which container and which serialization format to use. In this post I provide a summary of the various file and serialization formats.
Introduction
Before we start, let’s briefly remind ourselves what we’re talking about. A container is nothing but a data structure, or an object to store data in. When we transfer data over a network the container is converted into a byte stream. This process is referred to as serialization. The reverse, that is converting a byte stream into a container, is called deserialization.
The commonly encountered acronym ‘SerDe’ refers to the serialization/deserialization of data.
It tells applications how records are to be processed.
In databasespeak, a serializer is typically used when writing data (i.e. INSERT statements), whereas a deserializer is needed when reading (i.e. SELECT statements).
How ‘easy’ it is to convert a byte stream into an object and vice versa is one of the criteria for choosing one SerDe over another.
Row-Based vs Column-Based Storage
Storage systems can be divided into two categories: row-based and column-based, or columnar, storages. The difference is in the way data is stored.
Suppose we have a data set of ‘ordinary’ people and their alter egos:
| Id | First name | Last name | Alias | Residence |
|---|---|---|---|---|
| 1 | Bruce | Wayne | Batman | Gotham City |
| 2 | Jack | Napier | The Joker | Gotham City |
| 3 | Pamela | Isley | Poison Ivy | Gotham City |
| 4 | Peter | Parker | Spiderman | New York City |
| 5 | Tony | Stark | Iron Man | New York City |
| 6 | Selina | Kyle | Catwoman | Gotham City |
| 7 | Clark | Kent | Superman | Krypton |
In row-based storages, the records would be stored as they appear. The column boundaries would be roughly converted into a separator (e.g. a comma or semicolon); a fancy CSV file, if you will.
When you slap a compression algorithm on each record, it may be able to shave off a few bytes here and there, but by and large each record is composed of mainly distinct types of data and, more importantly, the contents are quite different.
In our example, we only have character data, except for the Id obviously, but I think you get the point nonetheless.
In a column-based storage, the columns rather than the rows are kept together:
Bruce:1|Jack:2|Pamela:3|Peter:4|Tony:5|Selina:6|Clark:7
Wayne:1|Napier:2|Isley:3|Parker:4|Stark:5|Kyle:6|Kent:7
Batman:1|The Joker:2|Poison Ivy:3|Spiderman:4|Iron Man:5|Catwoman:6|Superman:7
Gotham City:1|Gotham City:2|Gotham City:3|New York City:4|New York City:5|Gotham City:6|Krypton:7
In itself, that does not look too spectacular, does it?
All we have done is transpose the original matrix of data with a horizontal bar as a delimiter.
Each record now also has the identifier tacked onto it.
Note that the Ids are, especially in the absence of primary keys, best handled by the DBMS itself.
Generic row identifiers spring to mind, as for instance Oracle’s ROWID.
I have merely included the identifiers to explain the salient bits of columnar data stores.
Well, the reason we do add the Ids is that each record contains the same type of data and, as in the case with the residences of our (super-)heroes and nemeses, we see the same contents.
We can thus compress the data as follows:
Bruce:1|Jack:2|Pamela:3|Peter:4|Tony:5|Selina:6|Clark:7
Wayne:1|Napier:2|Isley:3|Parker:4|Stark:5|Kyle:6|Kent:7
Batman:1|The Joker:2|Poison Ivy:3|Spiderman:4|Iron Man:5|Catwoman:6|Superman:7
Gotham City:1,2,3,6||New York City:4,5|Krypton:7
If the table were bigger, we’d also see the same kind of behaviour in the names: multiple repeating names that we can summarize.
One of the advantages of columnar data stores is OLAP: reading and/or aggregating (small) subsets of columns.
For instance, if you want to compute the longest Alias in our previous table, you simply have to fetch the columnar record that contains all the aliases and pick the longest.
In a row-based data store, you may have to jump all over the place because the individual records are split across many blocks.
Thanks to column sparsity and compression, columnar data stores also typically have lower disk usage.
On the flipside, OLTP (i.e. writing few records frequently) and streaming are two use cases where columnar data stores are at a disadvantage. Suppose, for example, that Selina Kyle moves to Los Angeles: we’d have to remove her identifier from Gotham City and create a new one, instead of simply updating one cell. Similarly, single-row record reads are slower because they have to be pieced together (i.e. deserialized) from different ‘lines’.
File Formats in Hadoop
In essence, you can store any type of data in Hadoop. It’s what you can then do with it that determines how useful the stored data really is.
Typically, though, we data people work with structured or semi-structured data. And in those cases, Hadoop offers simple text files (e.g. CSV, XML or JSON), which are somewhat unsurprisingly known as TextFiles, a binary version called SequenceFiles, Avro, RCFile, ORC, and Parquet. Obviously, TextFiles are the only file format listed that supports unstructured data.
TextFiles are by default not compressed and they cannot be split. This is why a more compact, binary representation with SequenceFiles is often recommended.
There are various pages dedicated to picking the right file format for a particular use case. For instance, Cloudera talk about file formats in relation to Impala.
Then there is the ‘small files problem’. Huge amounts of small files can be stored in an Hadoop Archive (HAR) file, as having loads of tiny files in Hadoop is not the most efficient option. Nevertheless, HAR files are not splittable, which is something to keep in mind.
Serialization Formats in Hadoop
The information shown in the table below has been collected from various sources, notably Hadoop Application Architectures, Hadoop – The Definitive Guide, Apache Hive Essentials, and the documentation of the respective contestants:
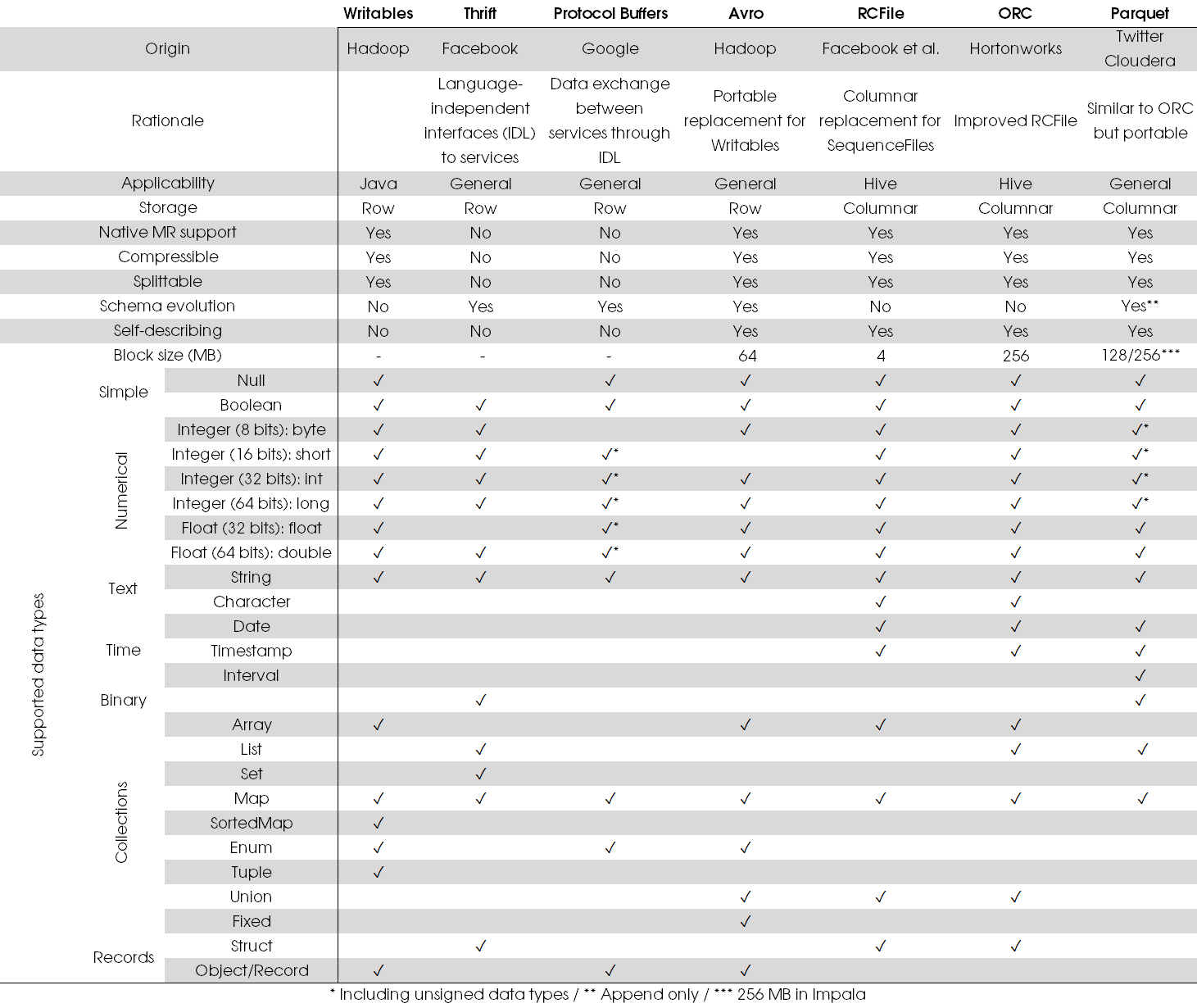
Please note that IDL is an acronym for interface description language. I have mimicked data type nomenclature of third-generation programming languages, because there seems to be little consensus among 4GLs in the Big Data environment: most (relational) database engines have a common language.
Anyway, why would you care about these characteristics?
Well, splittability allows files to be cut at any line and ingested and/or processed in parallel. This is great for huge files and also the reason why XML and JSON files are not ideal; JSON records are cool though. You cannot take an arbitrary XML file and a pair of scissors and cut the file into pieces; records are smeared out over potentially many lines. This means that the chunks are not independent, which ruins parallelization.
Similarly, a large block size (when deserialized) allows the engine to skip data that is not relevant to your queries, provided of course that the entire block is of no interest to your particular problem. Small blocks also require the name node to manage loads of metadata, which isn’t ideal either. The default block size in Hadoop is 64 MB (or 128 MB in Cloudera’s distribution).
What is more, a schema that is capable of describing itself (with comments or annotations) enables people with limited or no knowledge of the data and its format to understand what they’re looking at. This of course depends on the quality of the descriptions.
Observations
Thrift and Protocol buffers are mainly used for remote procedure calls (RPCs). Avro can also be used to that end.
ORC has light-weight indexes stored in headers, which allows jumping over blocks that do not contain the relevant information; minimums, maximums, sums (where appropriate), and counts are automatically computed. Predicate push-downs are also supported.
ORC is not really used or usable beyond Hive. However, the community behind ORC intend to address that in a future release.
Interestingly, Parquet supports very few native data types, even though it has many boxes ticked in the table. The reason is that Parquet has logical types, which specify how binary data is to be interpreted by means of annotations. That way, many more data types are available even though only few encodings have to be implemented.
When you use Flume to ingest event data, text files are typically not recommended. Hence, the default HDFS sink is SequenceFile (a binary key-value format); you can use Avro too. Moreover, columnar formats are not ideal for Flume because they require batches to be created to compress the data.
Caveats
If you happen to be stuck on Hive 0.14 or below, columns names must be in lower case when using Parquet. This is a bug that has been fixed in more recent versions. Loads of bugs have been fixed since, so please move to more recent versions of Hive. One of my ‘favourites’ is the fact that map-joins on lateral views cause duplicates in Tez; it took a few moments to figure that one out.
Performance Considerations
That ORC really is an optimized version of RCFile is nicely illustrated in a deck of slides by Hortonworks.
IBM and Hortonworks have also compared the performance of the various containers and serialization formats, and the result is pretty clear: Avro and Parquet are best overall, that is, when it comes to size, reading, writing, and generating statistics.
So, there you have it. I hope this overview helps you on your way through the confusing zoo that is Hadoop.