Open-Source Data and Machine Learning Software by the Numbers
Let’s take a closer look at the more popular open-source tools for data engineering, machine learning, and container orchestration.
While popularity is by no means an indication of quality, it does show towards which technologies the industry converges. That can inform product management, especially with regard to integrations.
To gauge popularity, I shall look at open-source software available on GitHub, and focus on the number of stars on each repository as well as Google searches in the category ‘software’ over the past five years.
Why Google? It has been the world’s leading search engine for at least ten years straight, so it does capture trends fairly accurately.
Data Engineering
The chart below shows the number of stars on GitHub over time for various data processing frameworks. It has been produced with Star History.
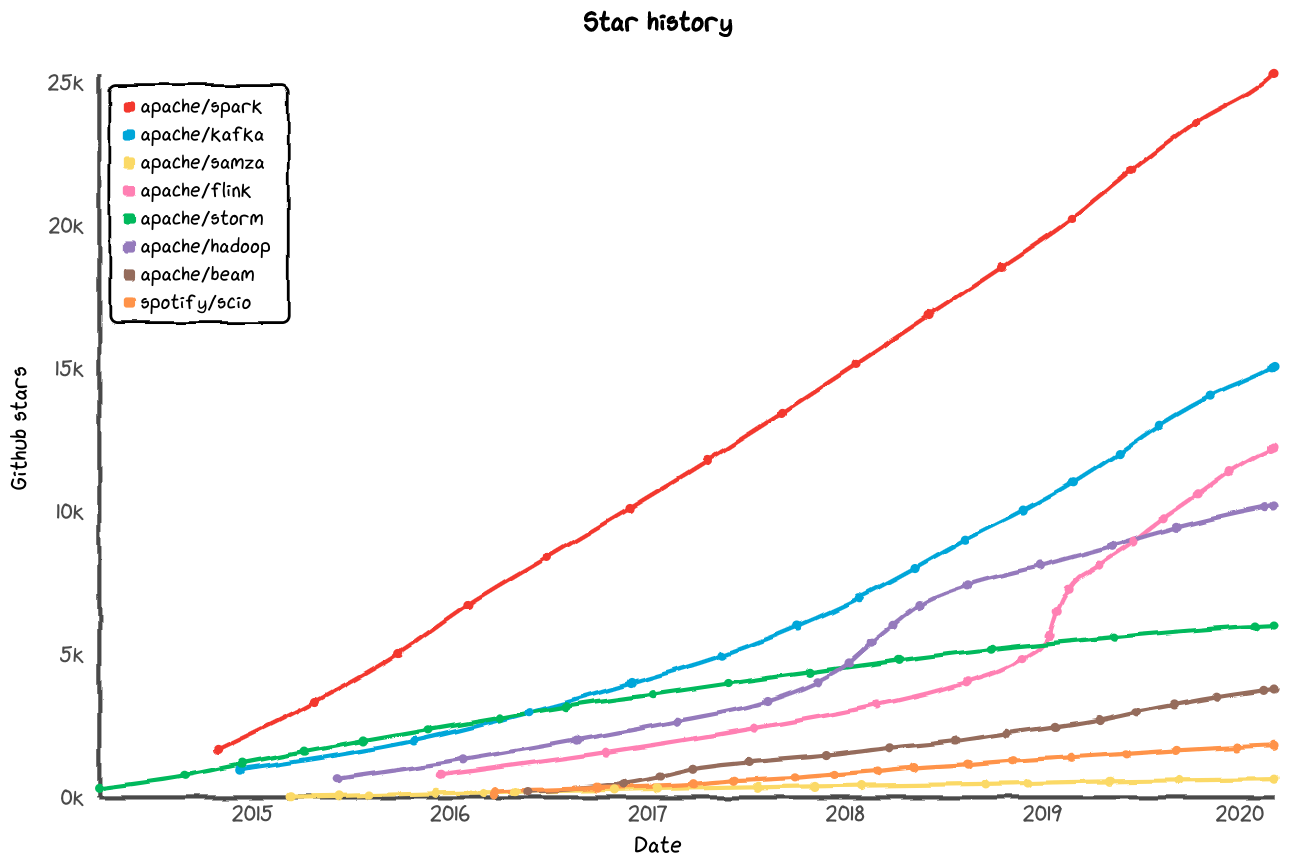
It’s obvious that Apache Spark leads the pack on GitHub as well as Google.
Scio is Spotify’s open-source Scala API for Apache Beam, so not a data processing framework. In fact, Apache Beam is itself an SDK, for which you choose different runners (e.g. Spark, Flink, or Google Cloud Dataflow).
Workflow Management
Spotify’s Luigi has been losing ground to Airflow, which was created by Airbnb, and Argo is trending in Google web searches.
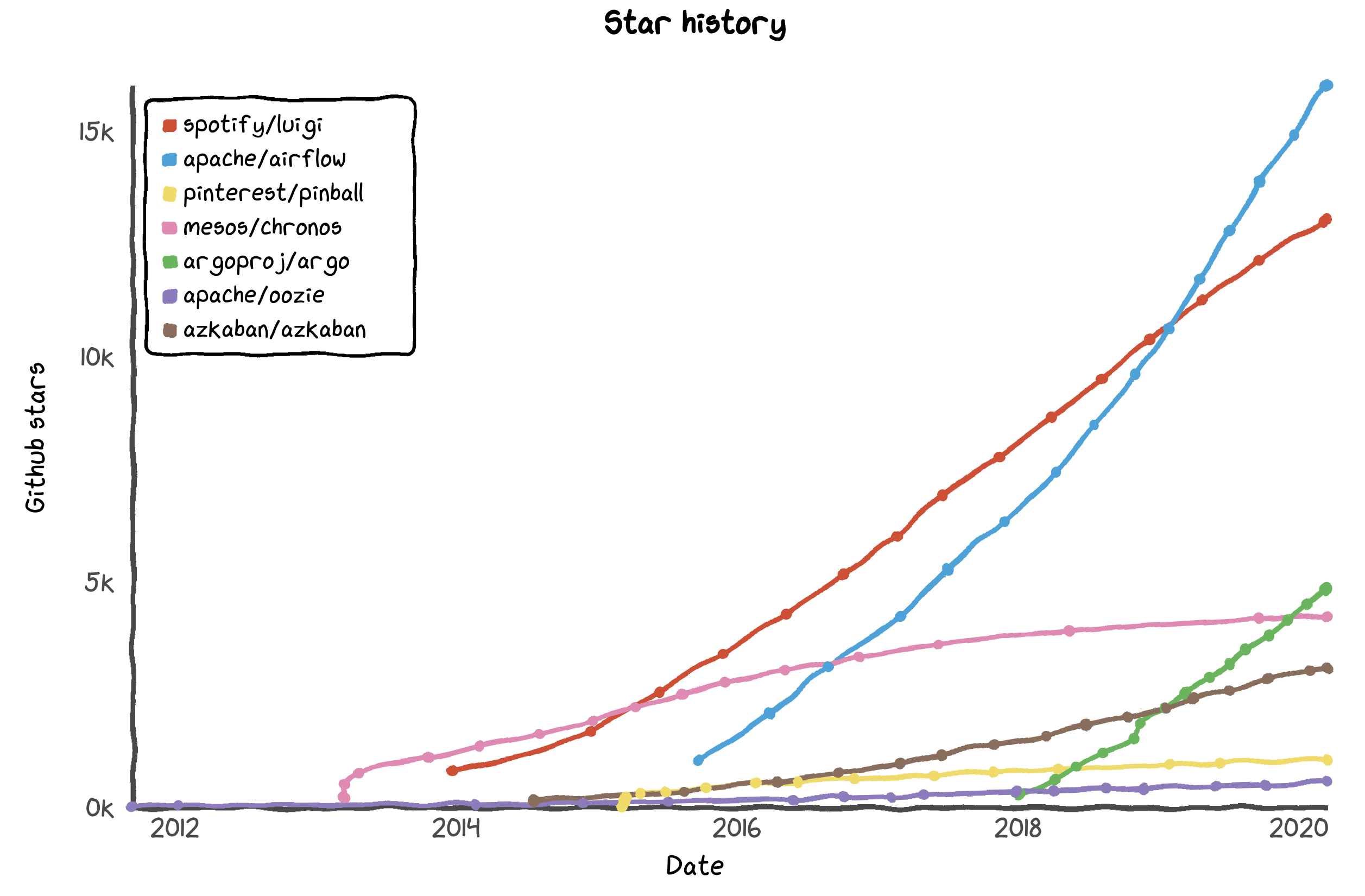
Chronos is a fault-tolerant alternative to cron, which is perhaps not a workflow scheduler in the same sense as Airflow and Luigi. Please note that Pinball is no longer maintained.
Uber’s Cadence and Conductor by Netflix are not included, as these tools are geared towards microservices and not data pipelines.
Machine Learning
TensorFlow rules the machine learning libraries:
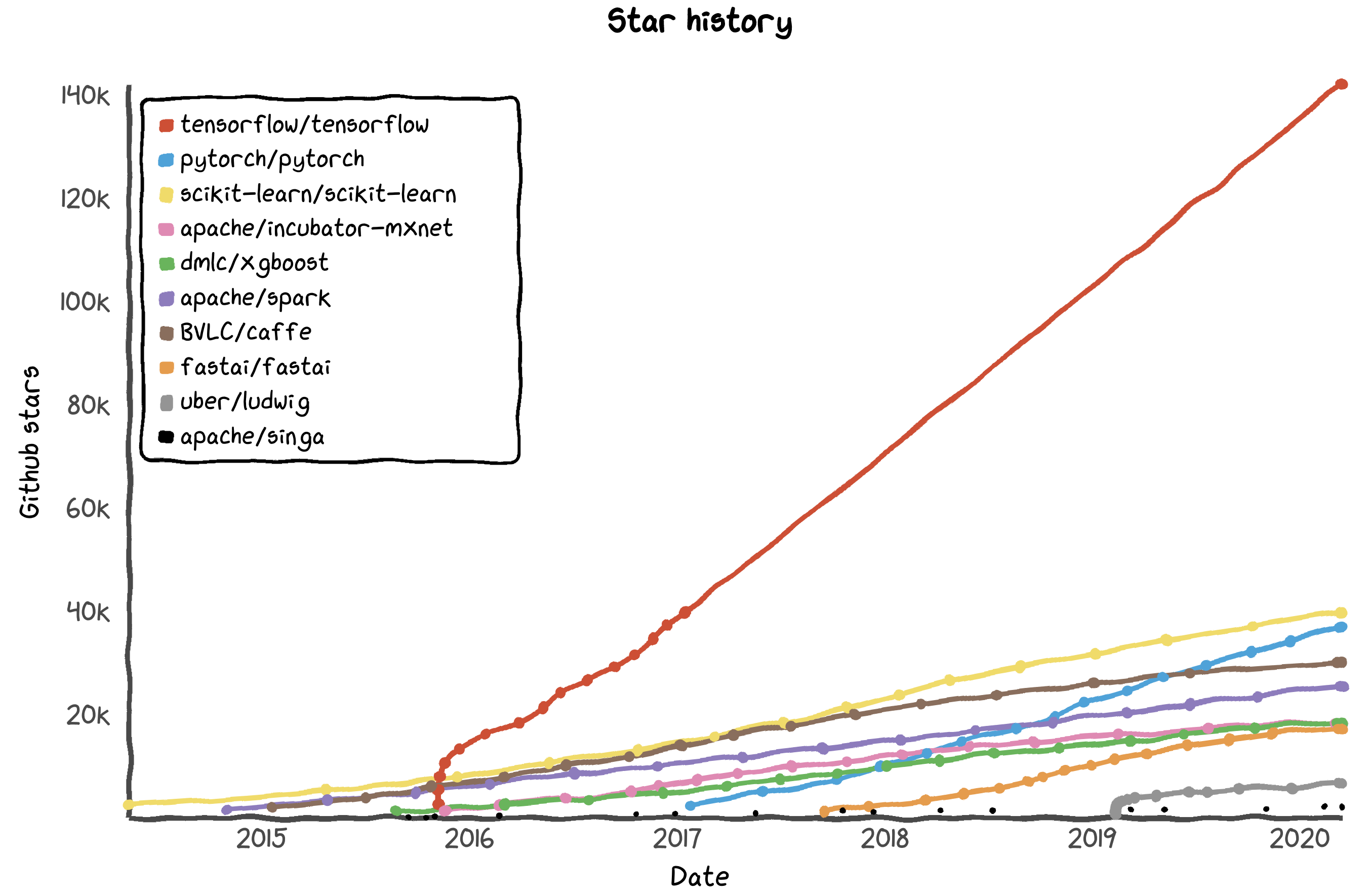
When you look on Google Trends, you see that TensorFlow is almost twice as often sought as the next framework: PyTorch. The latter is catching up though.
Storage
For databases of all kinds, DB-Engines is the standard popularity meter. What is interesting to note is that certain trends visible in GitHub are not transparent in DB-Engines’ ranking.
SQL: OLTP
PostgreSQL is the open-source leader of relational OLTP databases on GitHub:
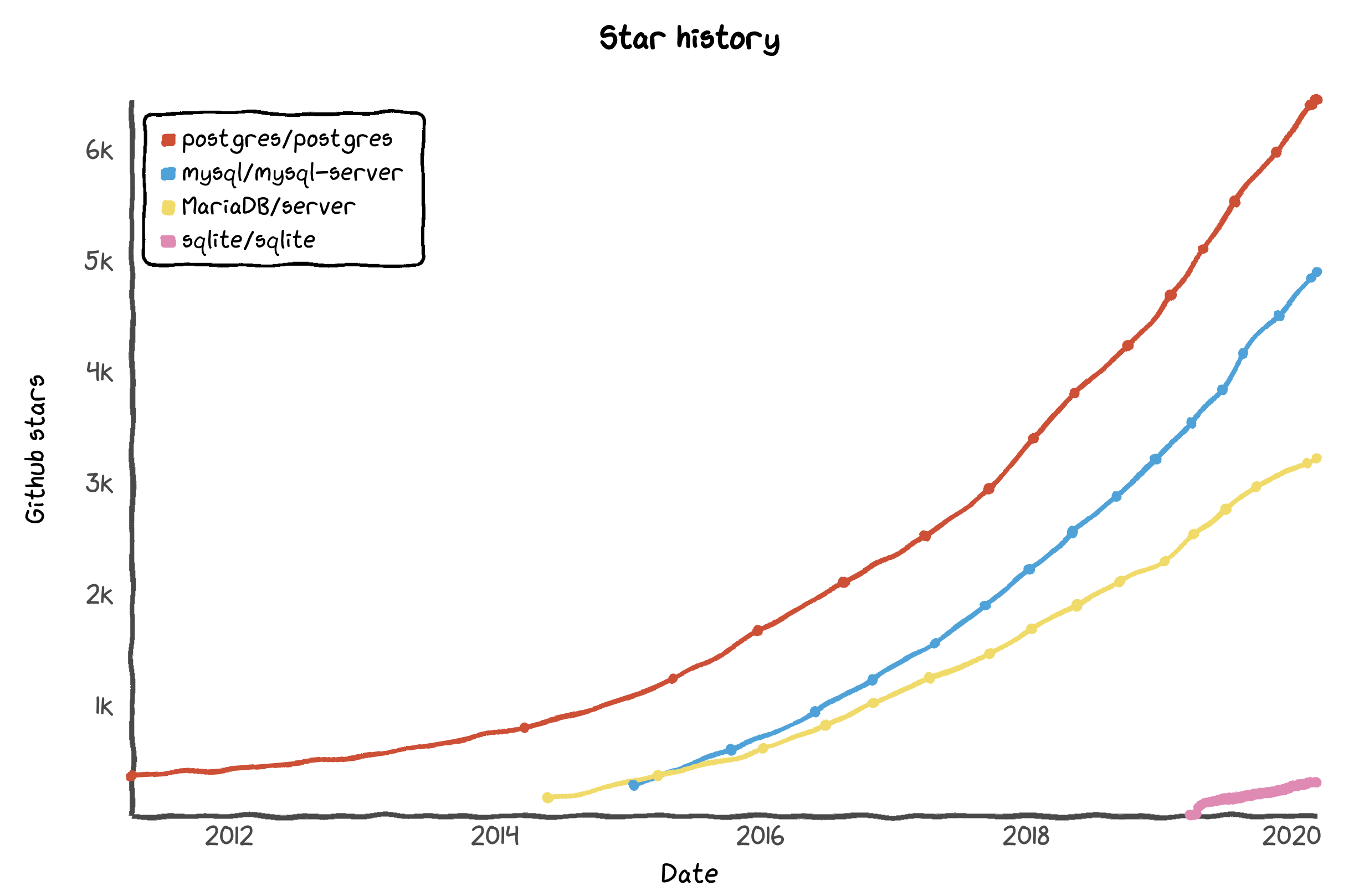
While DB-Engines lists both OLTP and OLAP RDBMSs in the same category, MySQL is its favourite. In terms of Google searches, MySQL is way ahead of Postgres, so Google and DB-Engines agree on that.
Please observe that some projects are mirrored to GitHub (e.g. PostgreSQL and SQLite), so stars and other statistics may not be perfectly representative of the project’s main activity elsewhere.
SQL: OLAP and SQL Engines
Presto leads in the category of data warehouses and SQL engines:
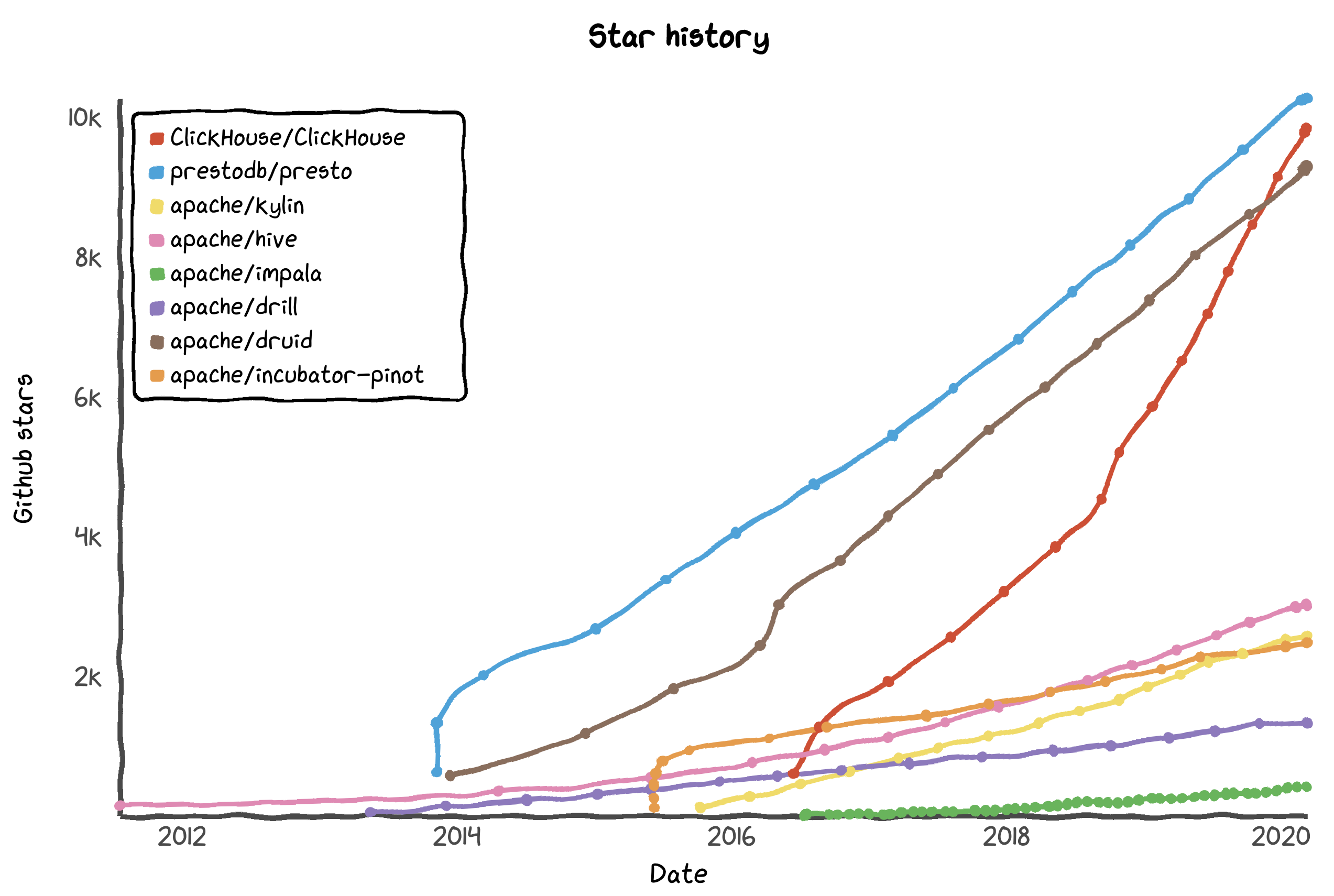
Some entries are (distributed) SQL query engines and not relational databases per se. These include Presto, Hive, Drill, and Impala. Hive, for example, is a SQL engine on top of Hadoop.
Combined
When you compare OLTP databases and OLAP engines together, Presto and ClickHouse are ahead of PostgreSQL on GitHub, even though DB-Engines lists these in 26th and 39th position, respectively. Below I list the combined RDBMSs and query engines based on their GitHub stars and contributors (as of this writing). The rank shown is from DB-Engines where available.
| Name | Stars | Contributors | Rank |
|---|---|---|---|
| Presto | 10,266 | 340 | 26 |
| ClickHouse | 9,831 | 404 | 39 |
| Druid | 9,296 | 331 | 56 |
| PostgreSQL | 6,444 | 33 | 4 |
| MySQL | 4,887 | 74 | 2 |
| MariaDB | 3,227 | 221 | 8 |
| Hive | 3,013 | 194 | 10 |
| Kylin | 2,570 | 167 | – |
| Pinot | 2,474 | 101 | – |
| Drill | 1,349 | 126 | 46 |
| Impala | 403 | 127 | 22 |
| SQLite | 298 | – | 7 |
The lack of contributors for SQLite is likely due to the fact that the GitHub repository is a mirror.
Google agrees with DB-Engines, which indicates that the community on GitHub is perhaps not entirely representative of popularity in general.
NoSQL
Key-Value Stores
Both DB-Engines and GitHub agree that Redis is the most popular key-value store:
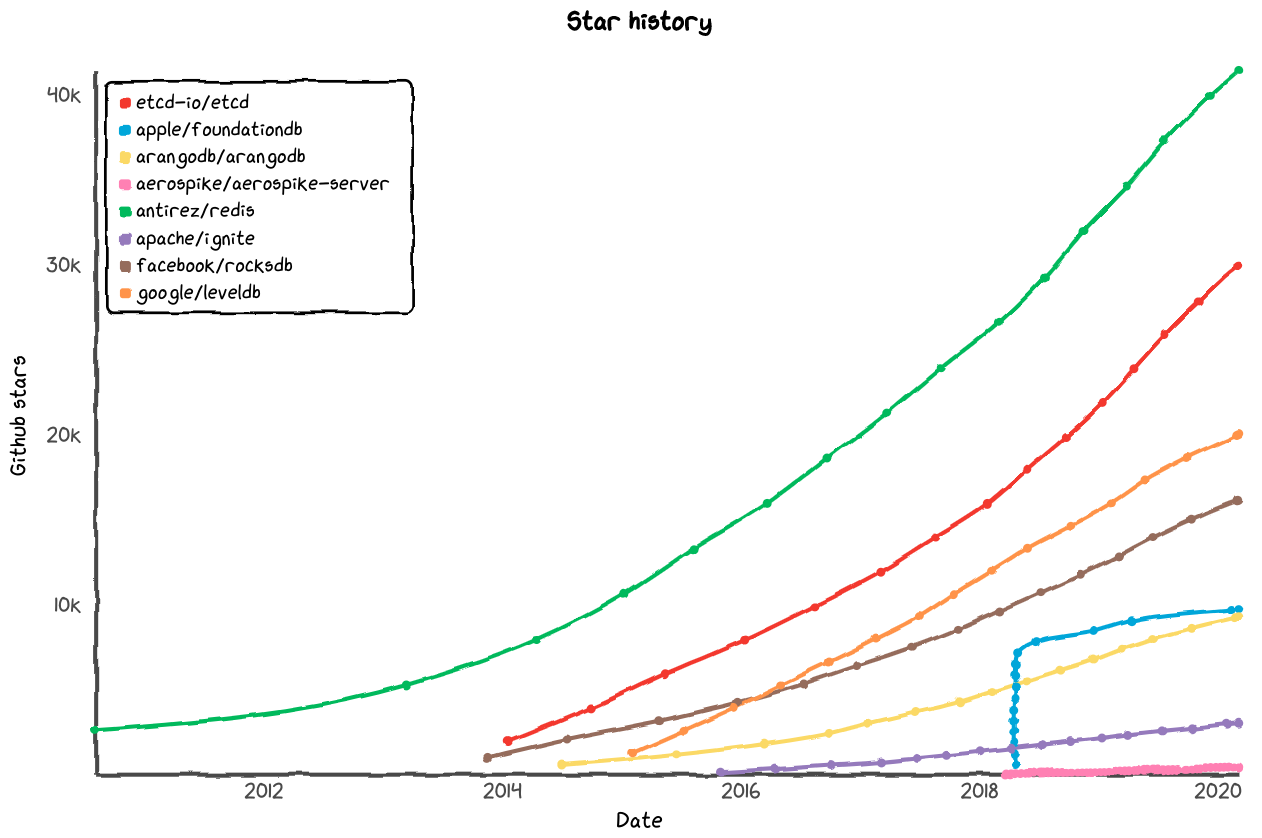
Aerospike does not have nearly as many stars as DB-Engine’s ranking (6th) suggests.
Document Stores
In the category of document-oriented databases, GitHub has Elasticsearch, RethinkDB, and MongoDB as the top 3, whereas DB-Engines sees MongoDB as the current leader:
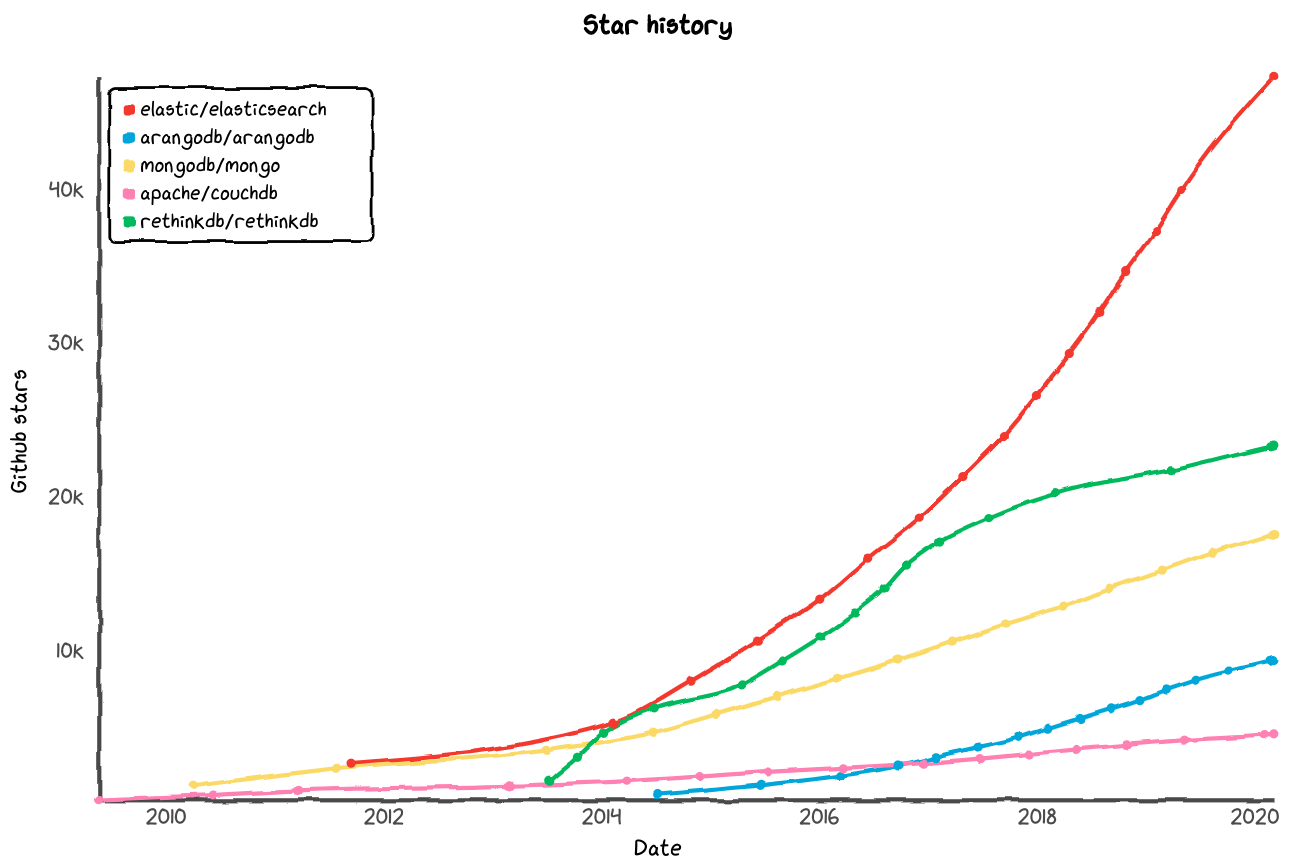
Note that Elasticsearch is a search engine for documents, which is why DB-Engines has it listed as the most popular search engine rather than a document store.
Wide Column Stores
Cassandra is the queen of wide column stores:
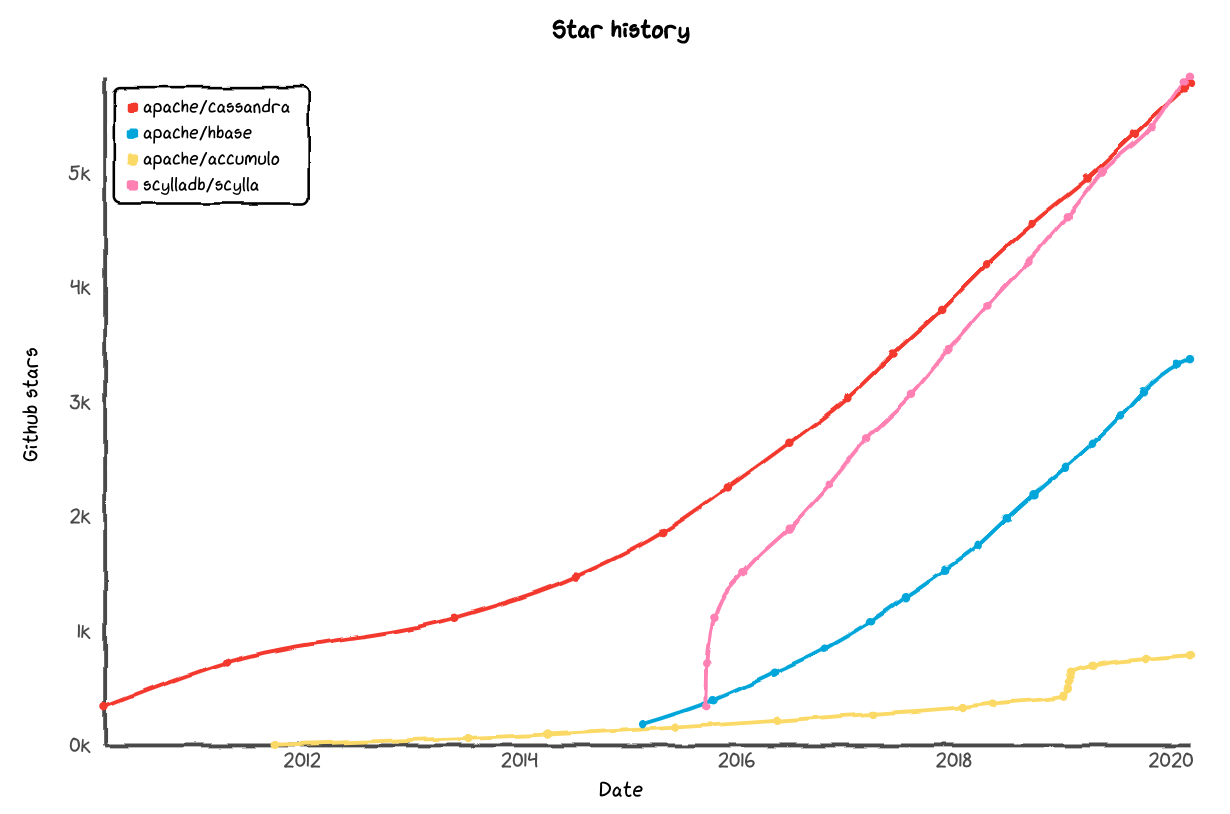
ScyllaDB has been catching up to Cassandra on GitHub although it’s in a stable 8th position according to DB-Engines.
Graph Databases
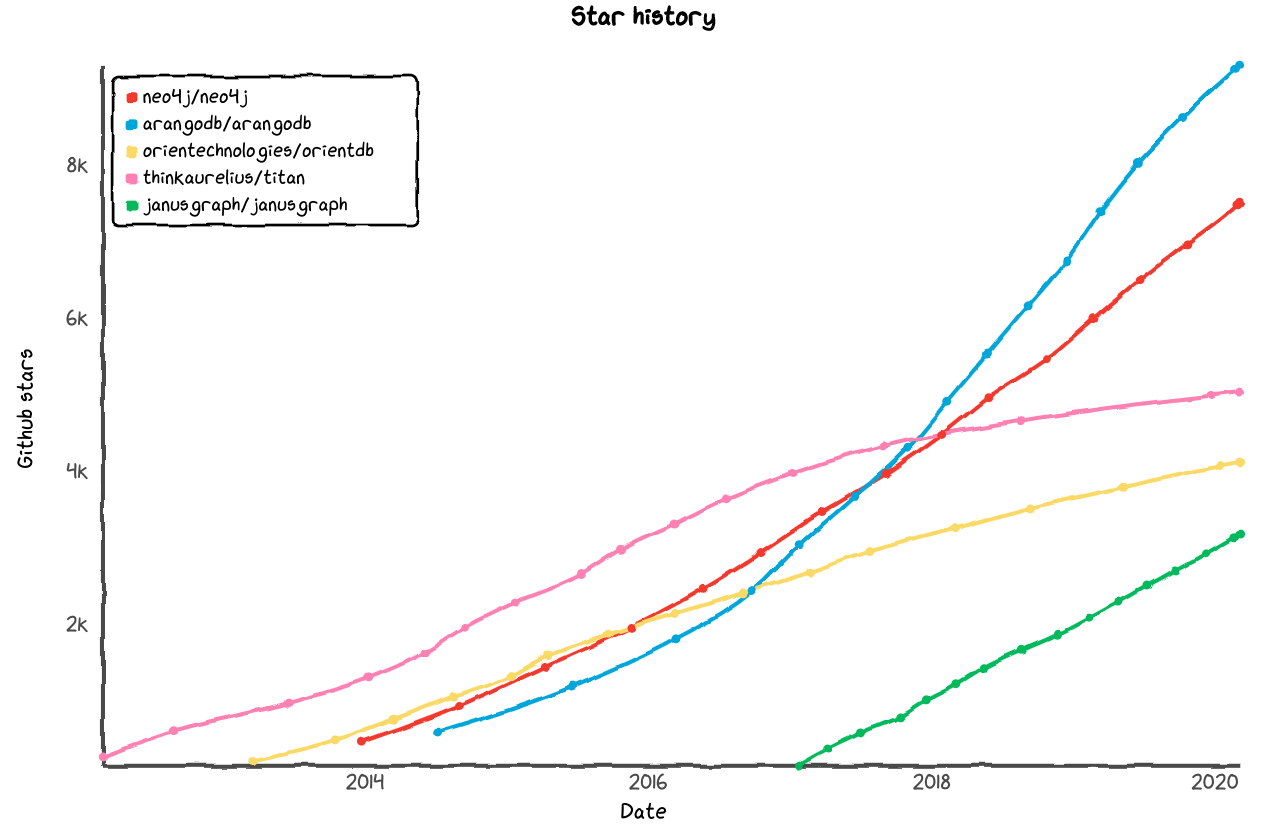
For graph databases, Neo4j is still ahead, although ArangoDB, a multi-model NoSQL database, is gaining in popularity:
Container Orchestration
Undoubtedly, Kubernetes is captain of the container orchestrators.
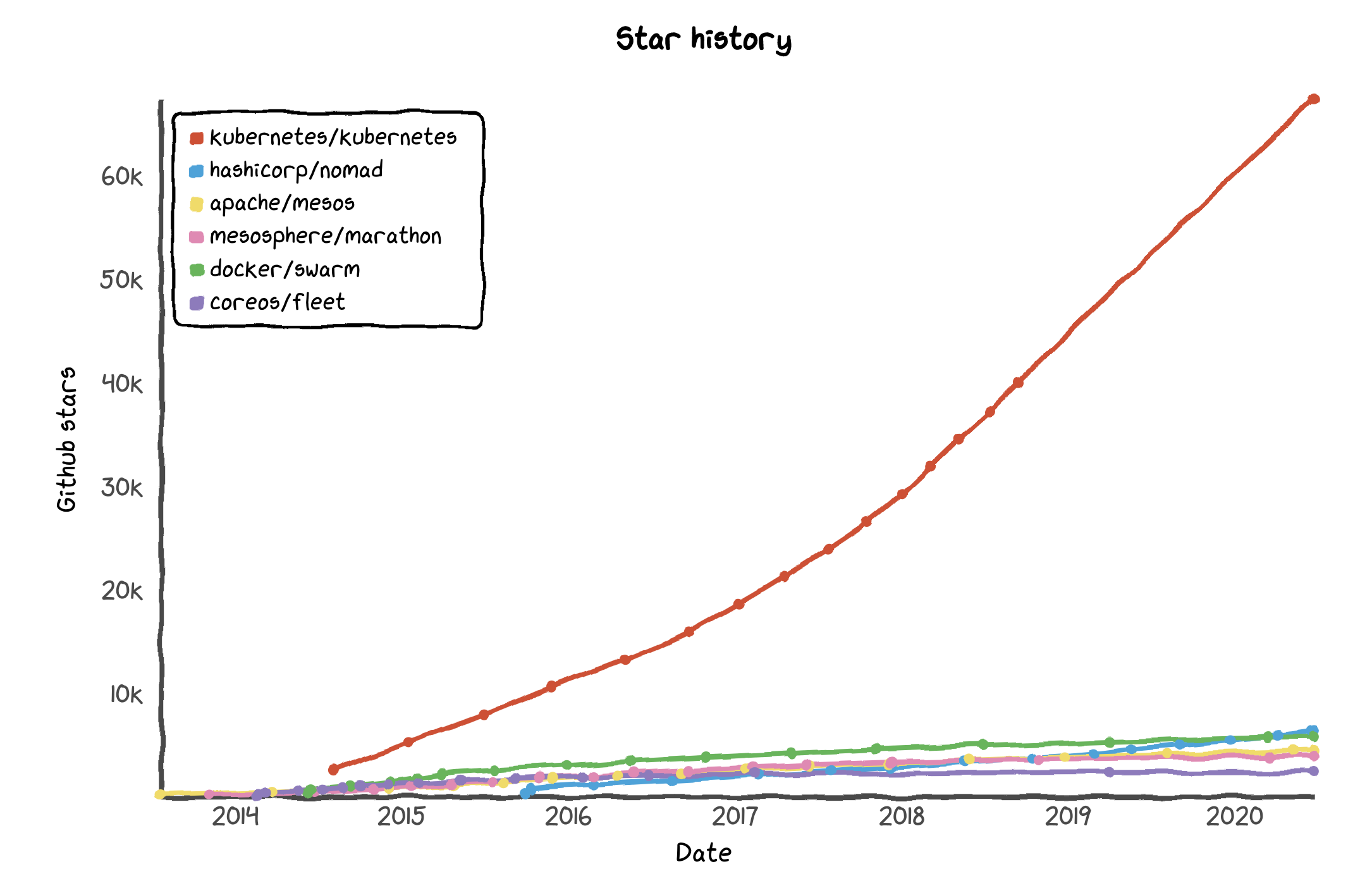
Mesos is not a container but rather generic workload orchestrator. Marathon is the direct competition of Kubernetes, but typically runs on Mesos, which is why I have included both.
As can be expected, web searches on Google back up Kubernetes’ supremacy.