DevOps for ML
While DevOps can be applied to machine learning, there are subtle differences that may not be obvious to the casual observer.
The key difference can be expressed succinctly as: we ship the factory, not merely the final product. But what does that really mean?
DevOps
In DevOps, we deploy the final product, an artefact generated by a CI/CD system, such as a container. Let’s say you are responsible for the payment component of an e-commerce company. Whenever a customer checks out their items, the backend needs to reach out to supported payment processors, such as Mastercard, PayPal, Stripe, Visa, and what have you. The code is changed whenever a bug is fixed, code is refactored, or a new processor is added, upon which that code is reviewed, tested, and of course redeployed.
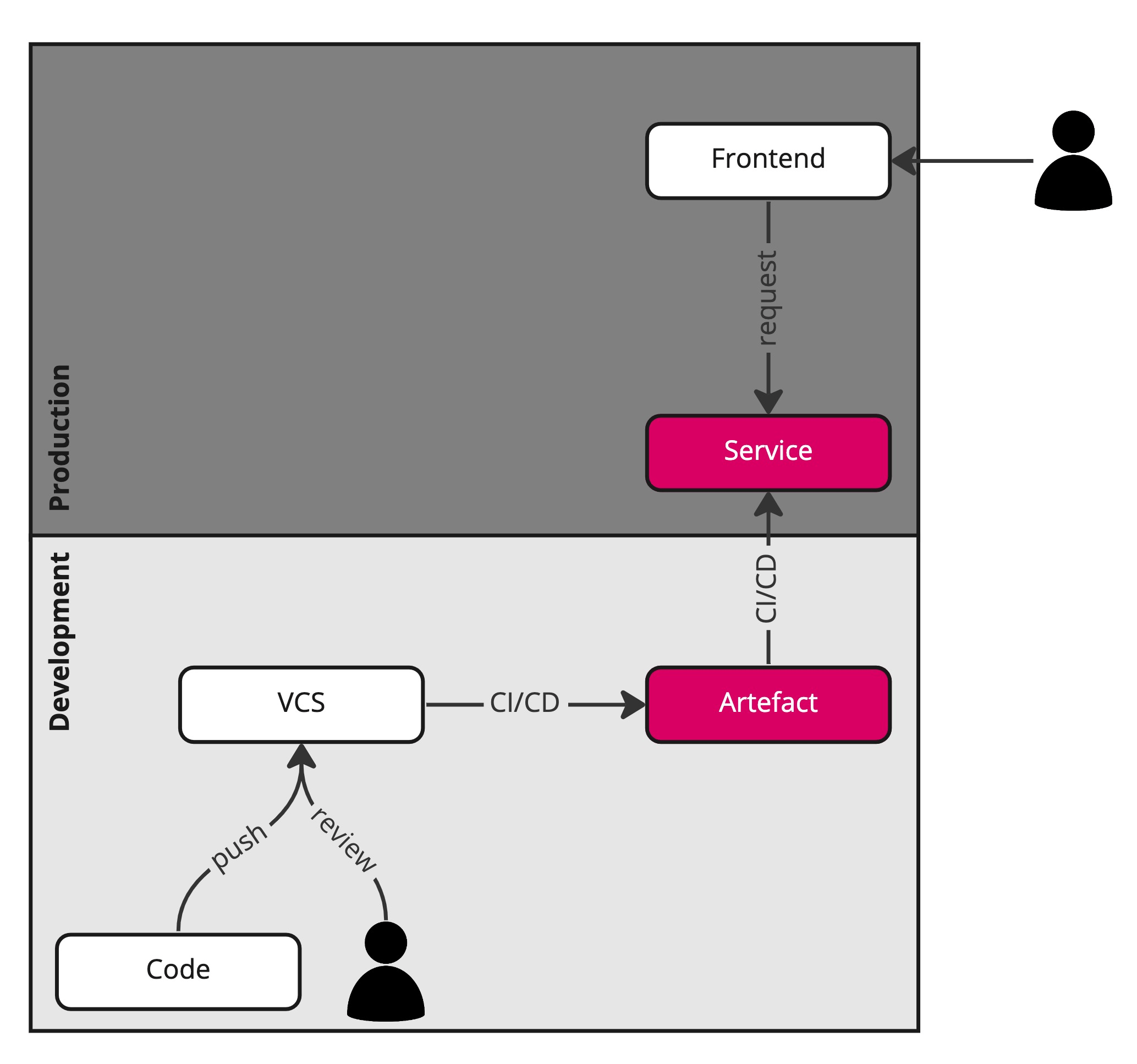
In case of sudden traffic spikes, the service can auto-scale based on the configuration provided. In most cases, no reconfiguration with subsequent redeployment is required.
Likewise, if users suddenly buy completely different products off your online store, the backend stays the same. This can happen during the holidays or around special events, because of end-of-season sales, as a reaction to major world events, or organically as user preferences shift over time.
D/MLOps
Not so in machine learning. Shifts in behaviour can significantly affect the quality of product recommendations. Since these recommendations often generate substantial revenue, that has a direct negative impact on the company’s bottom line.
The fully trained or tuned model is the artefact that is used inside the recommendation service (with possible pre- and/or post-processing applied to requests to the service), but retraining the model does not necessarily require any code changes if the process is parameterized to run over, say, the last four weeks of data or similar. That data and derived features also have to be regenerated, which may or may not happen automatically.
If source data is refreshed regularly, an orchestration layer is already present that knows how to kick off new data processing (ETL) jobs based on the configuration provided. Common orchestration tools include Airflow, Dagster, Flyte, and Prefect. These tools typically come with a built-in scheduler, pipeline monitoring, data observability, and of course automatic retries with exponential back-off, as data pipelines can often fail due to transient issues.
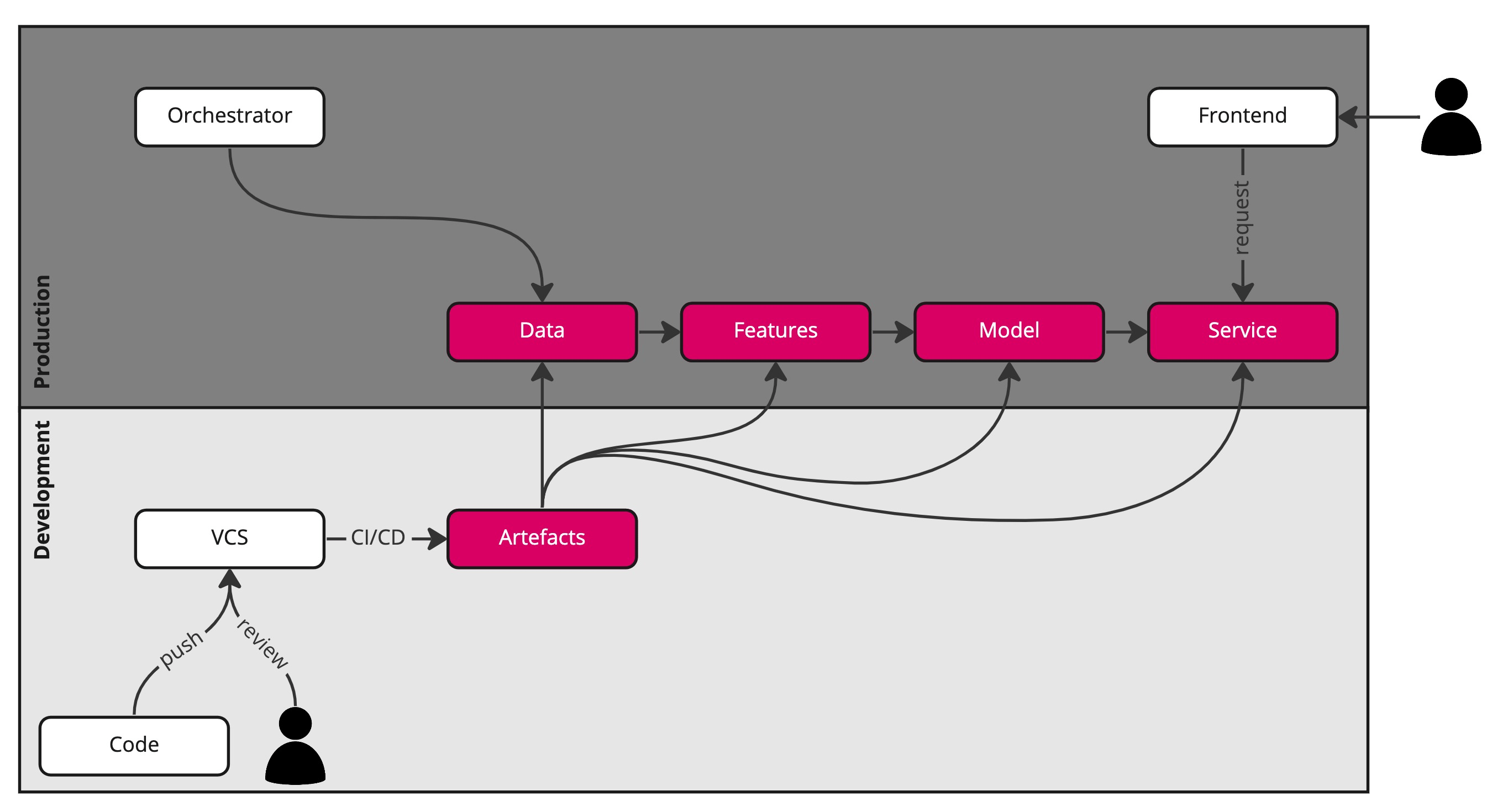
The workflow is highly stylized as it excludes the creation of a split in training, test, and validation data, feature selection, neural architecture search, hyperparameter tuning, model validation, and of course logging and monitoring. Note that the data box can be a multi-step pipeline itself.
D/MLOps is the combination of DataOps and MLOps, and what is deployed is the factory that knows how to make the data, features, model, and service based on the pipeline definition (blueprints) and artefacts (raw materials). That factory ensures proper versioning of data, features, and models, and only pushes trained/tuned models to (shadow) production if these are better than baseline and safe to serve (quality control). If user behaviour changes over time or suddenly, that is immediately reflected in the data, features, model, and recommendation service, but only if these are automatically refreshed.
If only the trained model inside a prediction microservice (final product) were shipped rather than the whole pipeline with its artefacts (factory), the recommendations would not always match current user preferences, and each of the steps would have to be recomputed manually. That is pretty tedious and can easily lead to errors.
MLOps
There is a way to simplify the flow outlined by means of a feature store. A feature store decouples the DataOps from the MLOps.
The DataOps flow is separate from the MLOps flow, which matches how responsibilities are typically split: data engineering vs data science. The data and features are automatically generated and versioned, so the model pipeline only has to be able to extract the relevant features from the feature store and use these to train or tune the model, upon which the same verify-and-push functionality kicks in.
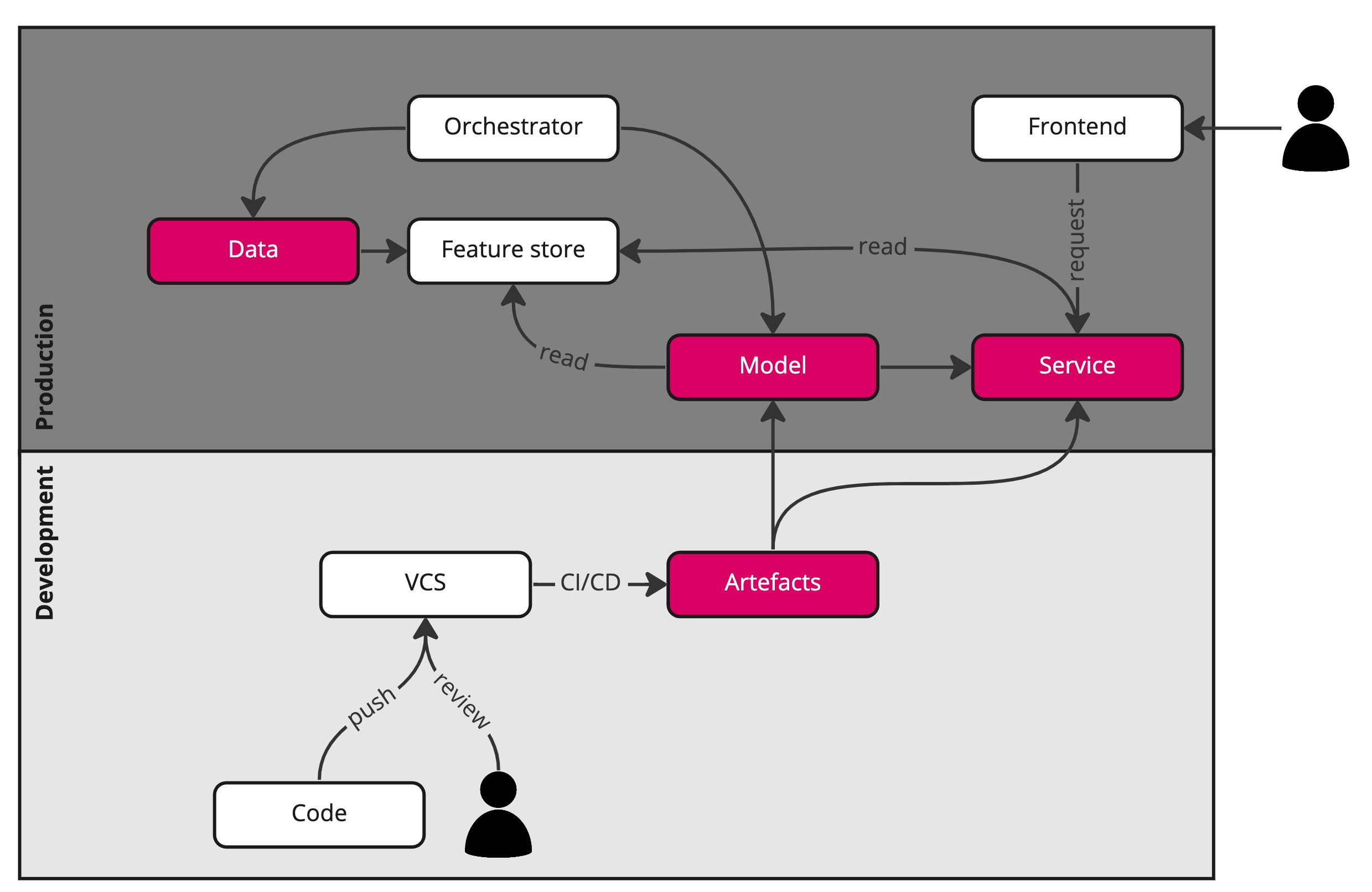
When MLOps has been decoupled from DataOps by means of a feature store, we ship the assembly line: the pipeline and artefacts that train/tune the model and wrap the trained model in a scalable service, provided it is good to go. In D/MLOps, we ship the entire factory: the pipeline and artefacts that regenerate the data, features, model, and ultimately package the trained or tuned model in a service. What we ship in DevOps is an artefact, that is, the final product.
Of course, DevOps, DataOps, MLOps, D/MLOps cannot fix a broken mindset: too many companies do not see the value of data and machine learning, because they treat initiatives as projects, not products. No machine learning platform can solve that for you. Only you can.