How to Multiply Across a Hierarchy in Oracle: SQL Statements (Part 1/2)
Hierarchical and recursive queries pop up from time to time in the life of a database developer. Complex hierarchies are often best handled by databases that are dedicated to such structures, such as Neo4j, a popular graph database. Most relational database management systems can generally deal with reasonable amounts of hierarchical data too. The classical example of hierarchical queries in SQL is the employees table: construct the organization chart with the CEO sitting at the top of the tree and all employees dangling from the branches on which their respective managers have placed their bottoms. While a direct acyclic graph of all company talent may tickle your fancy, I very much doubt it.
A while back I bumped into a hack for the Oracle Database. Since there is more than one way to skin a cat, I thought I’d share my thoughts about hierarchical queries and the hack I picked up. The main question of this post will be: How do I calculate the product of a column (think: yield) along each branch of a tree (i.e. yield for an entire line or sequence of steps based on the yield per step)?
The Product
Let’s start with the easiest part.
How do you calculate the product of a bunch of values for each group?
Well, Oracle does not directly offer a PRODUCT() or MULTIPLY() function, but fortunately we can create it without much ado. 1
If you have paid any attention at calculus, you may remember logarithms.
Yes, logarithms!
There happens to be one rule that says that the natural logarithm of the sum of two positive numbers is the product of the natural logarithms of those numbers: LN(a + b) = LN(a) * LN(b), which I have already written in SQL.
The inverse function gives us EXP( LN ( x ) ) = x for all finite, positive x , so that we can write the following: a * b = EXP( LN( a * b ) ) = EXP( LN(a) + LN(b) ).
The first equality is true because of the definition of the inverse function and the second equality holds because of the product identity of logarithms mentioned at the beginning of the paragraph.
And there you have it: EXP(SUM(LN(col_name))) gives us our product function using built-in aggregate functions.
Hierarchical Queries
Oracle Database offers two ways to build hierarchies: the hierarchical query clause (START WITH ...
CONNECT BY) and, as of 11.2, recursive factored subqueries (using the WITH clause), which are known in the world outside of Oracle as recursive common table expressions (CTEs), which is a much nicer name, don’t you think?
I shall cover both methods but before I do that, I need to set up the necessary data structures. I’ll dispense with primary keys and constraints for the sake of simplicity.
-- set up table and index
CREATE TABLE hierarchy_example
(
id NUMBER
, prior_id NUMBER
, yield NUMBER(3,2)
);
CREATE INDEX ix_hierarchy ON hierarchy_example(prior_id, id);
Now, I shall let PL/SQL do the legwork for me because I am lazy and know where I want to go with this and the next post:
DECLARE
l_seed BINARY_INTEGER := 16; -- allows reproducible results
l_num_rows NUMBER := 1000; -- number of rows to be inserted
l_num_anchors NUMBER; -- number of anchor rows inserted to eliminate cyclic references
l_conn_rows NUMBER; -- number of connected rows without cyclic references
l_start_ts TIMESTAMP; -- start time of PL/SQL block
l_end_ts TIMESTAMP; -- end time of PL/SQL block
BEGIN
l_start_ts := SYSTIMESTAMP;
-- set seed
DBMS_RANDOM.SEED(l_seed);
-- generate data and insert
INSERT INTO hierarchy_example ( id, prior_id, yield )
WITH raw_data AS
(
SELECT
ROWNUM AS id
, CEIL( l_num_rows * DBMS_RANDOM.VALUE ) AS prior_id -- ROUND can reference non-existent id = 0
, ROUND( DBMS_RANDOM.VALUE, 2 ) AS yield
FROM
DUAL
CONNECT BY
ROWNUM <= l_num_rows
)
SELECT id, prior_id, yield FROM raw_data;
-- break cyclic references
UPDATE
hierarchy_example
SET
prior_id = NULL
WHERE
id IN
(
SELECT
DISTINCT id
FROM
(
SELECT
id
, CONNECT_BY_ISCYCLE AS is_cycle
FROM
hierarchy_example
START WITH
prior_id IS NOT NULL
CONNECT BY NOCYCLE
id = PRIOR prior_id
)
WHERE
is_cycle = 1
);
l_num_anchors := SQL%ROWCOUNT;
COMMIT;
-- find the number of connected rows
SELECT
COUNT(*)
INTO
l_conn_rows
FROM
hierarchy_example
START WITH
prior_id IS NULL
CONNECT BY NOCYCLE
prior_id = PRIOR id;
l_end_ts := SYSTIMESTAMP;
DBMS_OUTPUT.PUT_LINE('Seed: ' || l_seed || ':');
DBMS_OUTPUT.PUT_LINE(' Inserted ' || l_num_rows || ' rows.');
DBMS_OUTPUT.PUT_LINE(' Created ' || l_num_anchors || ' anchor rows.');
DBMS_OUTPUT.PUT_LINE(' ' || TO_CHAR( l_num_rows - l_conn_rows ) || ' rows are still orphaned.');
DBMS_OUTPUT.PUT_LINE(' Elapsed: ' || TO_CHAR( l_end_ts - l_start_ts ) || '.');
END;
In the script, the factored subquery raw_data is used to generate random data to be inserted into the sample table hierarchy_example.
Because I rely on DBMS_RANDOM to generate the identifiers that define the paths through the data, there can be rows at the top of branches that are not parent (anchor) rows (i.e. prior_id IS NOT NULL) because of cycles; some children can even be their own parents, but we shall not concern ourselves with the intricacies of data inbreeding.
The number of inserted rows can thus be different from the number of connected rows, which is why I display the information at the end of the PL/SQL block.
Whether there are any cyclic references depends on the seed (l_seed) and the number of rows (l_num_rows).
For large l_num_rows the number of rows that are not connected due to cyclic references can be significant, which is why I have included an UPDATE statement, which does a bottom-up hierarchical search—notice the reversal of the PRIOR keyword in the CONNECT BY clause and the different START WITH clause—and resets the cyclic references, so that the top row is made an anchor row.
Cyclic references cause entire branches to be eliminated because of the NOCYCLE condition.
The CONNECT BY Clause
We can now execute the following query to generate the hierarchy, using the CONNECT BY syntax:
SELECT
LEVEL AS lvl
, id
, prior_id
, yield
, SYS_CONNECT_BY_PATH( id, '/' ) AS path
FROM
hierarchy_example
START WITH
prior_id IS NULL
CONNECT BY NOCYCLE
prior_id = PRIOR id
ORDER SIBLINGS BY
id;
The pseudocolumn LEVEL and the path column are purely informational.
As you can see the level shows the depth from the top of the hierarchy (because we started at the top and went down), and the path taken is visible in the path column.
The image below is a screenshot from SQL Developer for id = 601 and its descendants.
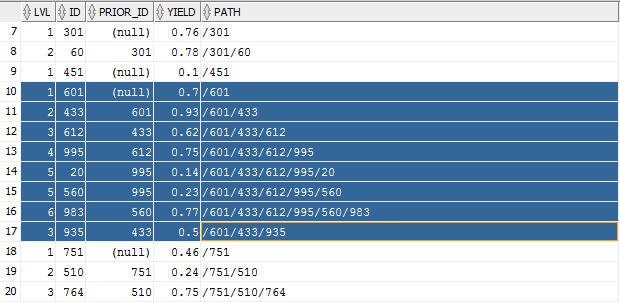
As you can see, at each level there can be multiple branches, which we need to take care of accordingly: the yield up to and including each step depends on the path taken and not on the depth from the root of each branch. Therefore, we cannot use an analytic function à la
MULTIPLY(yield)
OVER
(
PARTITION BY root_id
ORDER BY lvl ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT
)
with root_id as the alias of CONNECT_BY_ROOT( id ) and MULTIPLY() our aforementioned product function.
So, how do we multiply the yield by branch to obtain the yield up to a certain step, assuming that each row in the hierarchy_example table is a processing step?
Well, we have to follow the chain top to bottom, as before, and for each row we have to go back up to multiply the yield up to that point.
Below is the solution, where the outer query o goes down the hierarchy, and the inner query i goes back up:
SELECT
LEVEL AS lvl
, o.id
, o.yield
, (
SELECT
ROUND( EXP(SUM(LN(i.yield))), 2 ) -- only two significant digits
FROM
hierarchy_example i
START WITH
i.id = o.id -- start with the row from the outer query
CONNECT BY NOCYCLE
i.id = PRIOR i.prior_id -- reverse direction of PRIOR to go back up
) AS yield_to_step
, CONNECT_BY_ROOT( o.id ) AS root_id
, SYS_CONNECT_BY_PATH( o.id, '/' ) AS path
FROM
hierarchy_example o
START WITH
o.prior_id IS NULL -- start with anchor rows
CONNECT BY NOCYCLE
o.prior_id = PRIOR o.ID -- go down hierarchy
ORDER SIBLINGS BY
o.id;
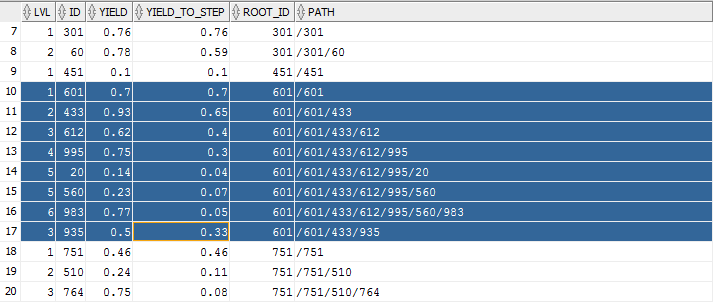
The results for the previous example are shown below.
Please note that for id = 983 the yield_to_step = yield * 0.07, which is the yield_to_step for its predecessor, id = 560, multiplied by the yield for the step itself.
The WITH Clause
The second release of Oracle 11g introduced factored subqueries for hierarchies. In for instance Microsoft SQL Server, these so-called recursive CTEs have always been a developer’s only option for hierarchical queries.
The idea of a hierarchical or recursive CTE is to have an achor similar to the START WITH clause and a recursive piece that can be used to loop through the result set:
WITH cte(lvl, id, prior_id, yield, root_id, path) AS
(
SELECT
1
, id
, prior_id
, yield
, id -- root_id = id for all anchors
, '/' || id
FROM
hierarchy_example
WHERE
prior_id IS NULL -- achors
UNION ALL
SELECT
r.lvl + 1
, d.id
, d.prior_id
, d.yield
, TO_NUMBER( REGEXP_REPLACE( r.path, '/([[:digit:]]+)($|/.+)', '1' ) )
, r.path || '/' || d.id
FROM
hierarchy_example d
INNER JOIN
cte r
ON
d.prior_id = r.id -- recursion
WHERE
d.prior_id IS NOT NULL -- ignore anchors
)
SELECT * FROM cte ORDER BY path, lvl;
This syntax is a bit cumbersome and the extraction of the root_id for the path is not very elegant but it does get the job done.
One advantage is, however, that with a few tweaks we can create the hierarchical multiplication query.
All we have to do is add the yield_to_step column in the definition of the factored subquery, which is nothing but the product of the yield for the row and the yield_to_step of the row’s predecessor.
Because we recursively step through the data we do not need our multiplication function from before.
Pretty neat, n’est-ce pas?
WITH cte(lvl, id, prior_id, yield, yield_to_step, root_id, path) AS
(
SELECT
1
, id
, prior_id
, yield
, yield -- yield_to_step = yield for all anchors
, id -- root_id = id for all anchors
, '/' || id
FROM
hierarchy_example
WHERE
prior_id IS NULL
UNION ALL
SELECT
r.lvl + 1
, d.id
, d.prior_id
, d.yield
, ROUND( d.yield * r.yield_to_step, 2 ) -- simple column multiplication
, TO_NUMBER( REGEXP_REPLACE( r.path, '/([[:digit:]]+)($|/.+)', '1' ) )
, r.path || '/' || d.id
FROM
hierarchy_example d
INNER JOIN
cte r
ON
d.prior_id = r.id
WHERE
d.prior_id IS NOT NULL
)
SELECT * FROM cte ORDER BY path, lvl;
The regular expression looks for paths that start with /, which are all paths obviously, followed by one or more (i.e. +) digits: ([[:digit:]]+).
Because the subexpression is placed in parentheses we can reference it by its position: \1, as it is the first subexpression in the list.
The second subexpression, ($|/.+), tells Oracle that the number found by the first subexpression is either the last in the path ($, which is the end-of-line character) or followed by another forward slash (/) and a bunch of characters (.+) that we don’t care about.
The Hack: Native Dynamic SQL (NDS)
As you may have gathered from the SQL statements presented and discussed, the syntax for a basic recursive CTE is a bit more unwieldy but easier to extend with branch-specific aggregations once you have done the groundwork. The hierarchical query clause is more compact, but aggregation along the branches requires you to write a query that distracts from the elegance and clarity of the original solution.
Is there a way to make the hierarchical query clause with branch-specific aggregations less cumbersome?
Yes, there is! But before I’ll show you, let’s make a couple of observations that will aid in understanding the hack.
First, the SYS_CONNECT_BY_PATH function already looks suspiciously close to what we need: imagine we generate the path based on the yield instead of the id.
What we end up with for id = 995 is 0.7/0.93/0.62/0.75. ‘Hmm,’ you say as you scratch your noggin, ‘What if we replaced the forward slashes with asterisks?
That would look like a multiplication even though it’s still a string.’ Hold on to that thought, skipper, we’re nearly there!
Second, a riddle: What is a VARCHAR2 string but actually executes as if it were a query?
Dynamic SQL, madam!
And that, ladies and gentlemen, is the essence of the hack: create a function that executes the (string) expression inside a query and returns the result.
The function I shall use is the following:
CREATE OR REPLACE FUNCTION eval (expr_in IN VARCHAR2)
RETURN NUMBER
AUTHID CURRENT_USER
DETERMINISTIC
RESULT_CACHE
IS
PRAGMA UDF;
v_res NUMBER;
BEGIN
EXECUTE IMMEDIATE 'SELECT ' || expr_in || ' FROM DUAL' INTO v_res;
RETURN v_res;
END eval;
You could of course make the function a lot fancier with checks on the incoming expression, but that is not my intention here.
Anyway, I’ve informed Oracle that the function always returns the same result for the same input with the DETERMINISTIC option, and that Oracle should cache intermediate results as it may speed up computations for expressions already evaluated.
The UDF pragma is a compiler instruction that tells Oracle (12c) that I expect to execute the function primarily from SQL statements rather than PL/SQL blocks.
Context switches between the PL/SQL engine that executes user-defined functions and the SQL executor can become a performance bottleneck, but I’ll talk more about performance in the next post.
For now, all we have to do is:
- convert
yieldto a string withTO_CHAR(); - replace
/with*in theSYS_CONNECT_BY_PATHfunction call; - remove the leading asterisk with
SUBSTR(..., 2), or prefix the entire string with1; - evaluate the expression with our
evalfunction .
Putting it all together, we end up with the following query:
SELECT
LEVEL AS lvl
, id
, prior_id
, yield
, eval(SUBSTR( SYS_CONNECT_BY_PATH( TO_CHAR(yield), '*' ) , 2)) AS yield_to_step
, CONNECT_BY_ROOT ( id ) AS root_id
, SYS_CONNECT_BY_PATH( id, '/' ) AS path
FROM
hierarchy_example
START WITH
prior_id IS NULL
CONNECT BY NOCYCLE
prior_id = PRIOR id
ORDER SIBLINGS BY
id;
That’s pretty compact code, especially since we did not have to resort to the multiplication trick.
Summary
The code samples I have shown are not specific to manufacturing. Yield is a very simple example where multiplication along a branch of a tree-like structure makes sense: whatever material I ‘lose’ (i.e. scrap) at step N is lost at all steps from N+1 onwards. A similar situation occurs when you have to multiply discounts or raises along the branches of a product tree or organization chart, respectively. The queries can also be adapted easily to allow different aggregation functions.
Before you decide on a particular syntax, though, it’s best to look at the performance of each type of query. That is the topic of the next post.
-
User-defined aggregate functions can be created too, but they require a lot more effort. ↩